| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
Введение в SQL - 3 Краткое содержание: SQL - язык определения данных (продолжение) В этой статье мы продолжим изучать операции над объектами базы данных. Даваемый материал основан на предыдущих статьях цикла. Также полагаем, что читатель имеет теоретическую подготовку в области реляционной алгебры (например, см. статьи Alf'а в этом же разделе статей). Для работы нам по-прежнему будут нужны Microsoft SQL Server (предпочтительно) или Microsoft Access. Рабочая база данных Продолжим работу по созданию базы данных, которую начали в предыдущей статье. Вспомним физическую модель базы данных нашей упрощённой библиотеки (см. рисунок 1). 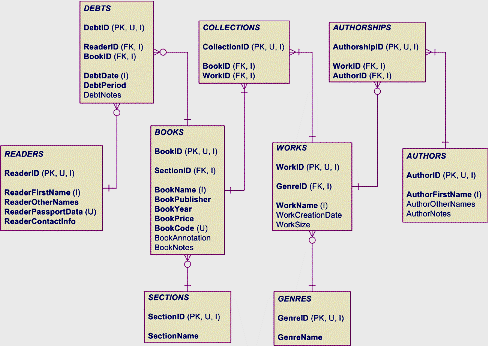 Рисунок 1 - Физическая модель базы данных Условные обозначения: PK - первичный ключ; FK - внешний ключ; I - индекс; U - уникальное значение; полужирным шрифтом выделены обязательные поля (не могущие быть пустыми - содержать NULL); на связях: чёрточка означает обязательное наличие записи, участвующей в связи; кружок - необязательное наличие (допустимо отсутствие связанных записей). Вспомним, что в прошлой статье мы начали создавать базу данных, и (если выполнены упражнения), имеем созданные полностью таблицы "Жанры" (Ganres) и "Отделы" (Sections), а также не полностью законченные таблицы "Авторы" (Authors) и "Читатели" (Readers). Приступим. (Не забудьте выполнить команду USE, чтобы сделать нашу базу данных текущей.) Таблицы (продолжение) Мы уже умеем создавать, изменять и удалять таблицы. Умеем добавлять, изменять и удалять поля таблиц. Знаем, как задаётся тип поля таблицы, как определить первичный ключ Теперь познакомимся с уникальными значениями. В таблице "Читатели" (Readers) поле "Паспортные данные" (ReaderPassportData) должно быть уникальным. Как и для первичного ключа, это означает, что в двух любых записях таблицы мы не должны найти одинаковых значений этого поля. Фактически, это поле является естественным первичным ключом, просто мы его не используем в качестве такового, так как оно текстовое. (Подробнее о причинах неиспользования мы поговорим ниже, когда будем разбирать связи.) Так как мы уже имеем первичный ключ, то могли бы и не заботится об уникальности поля "Паспортные данные" (или заботиться об этом в клиентском приложении, использующим базу данных), но для усиления защиты от некорректных (с точки зрения предметной области) данных мы добавим проверку на уникальность. Проверки уникальности полей прямо в базе данных незаменимы в крупных СУБД, поддерживающих параллельную работу нескольких пользователей с одной и той же таблицей. Для того, чтобы СУБД проверяла уникальность значений поля, в свойства поля можно добавить специальное определение.
(Напомним, что инструкции лучше выполнять по одной). Ключевое слово UNIQUE определяет свойство уникальности поля. К такому полю по умолчанию применяется свойство NOT NULL. В самом деле, если допустить свойство NULL, СУБД не сможет позволить без нарушения уникальности более чем одной записи содержать значение NULL. Часто возникают случаи, когда при создании записи некоторые поля можно заполнять заранее известным значениями. Например, в таблице "Задолженности" (Debts) есть поле "Дата начала задолженности" (DebtDate). Очевидно, что эта дата вносится в момент создания самой задолженности, поэтому мы можем установить для неё значение по умолчанию. Также по умолчанию мы можем устанавливать нормальную длительность задолженности (поле DebtPeriod), скажем, 2 недели - 14 дней. Значение по умолчанию определяется ключевым словом DEFAULT, которое задаётся как и любое другое свойство поля. Выражение, вычисляющее значение по умолчанию идёт сразу за ключевым словом. Так как таблица "Задолженности" (Debts) у нас отсутствует, то создадим её, пока не определяя связей и индексов.
В Access мне не известно способа через JetSQL задать значение по умолчанию для поля. Однако это можно сделать в дизайнере таблицы или макросом VBA. В примере использована функция SQL Server GETDATE(), возвращающая текущую дату. В других СУБД подобная функция может называться иначе, скажем, в Access это Date(). На примере функции даты видно, что значениями по умолчанию могут быть не только константы, но и вычисляемые выражения. Однако, использовать для вычисления значения по умолчанию поля самой записи в SQL Server запрещено. В таблице можно задавать вычисляемые поля. Такие поля поддерживаются не всеми СУБД, но достаточно распространены. Вычисляемые поля являются виртуальными: они не хранят в базе данных своих значений, а определяют их в момент чтения записи. Вычисляемые поля удобно использовать в тех случаях, когда выгоднее получить из СУБД уже готовую таблицу значений, а не обрабатывать все полученные записи на стороне клиентского приложения. Классическим примером вычисляемого поля является стоимость, получаемая умножением цены на количество товара. Определим в нашей таблице "Задолженности" вычисляемое поле "Срок возврата" (DebtDeadline), которое будем определять прибавлением длительности задолженности к дате начала задолженности. Для этого воспользуемся функцией SQL Server DATEADD().
Обратите внимание, что тип вычисляемого поля не задаётся. Теперь, при смене даты создания задолженности и/или допустимой длительности задолженности мы автоматически получим дату крайнего срока возврата книги в поле "DebtDeadline". В вычисляемых полях можно использовать другие поля записи. Вычисляемые поля не могут быть внешними ключами, не могут иметь свойство NOT NULL, не могут иметь значения по умолчанию, не могут быть заполнены данными при операциях вставки или обновления данных, однако могут быть частью первичного ключа или уникального значения, могут быть индексированы. Ещё одним объектом таблицы является проверка. Проверкой называется условие, при истинности которого разрешается операция над записью (создание, изменение, удаление). В проверках, как и в вычисляемых полях, можно использовать поля самой записи для определения условия. Проверку можно задать как свойство поля через ключевое слово CHECK и следующее за ним в скобках логическое выражение. Например, в таблице "Книги" (Books) есть два поля, нуждающиеся в проверке задаваемых данных. Значение поля "Год издания" (BookYear) не может быть больше текущего года, а значение поля "Цена" (Price) не может быть меньше 0,00. Создадим таблицу "Книги" (Books) пока без связей и индексов.
Для JetSQL в Access свойство CHECK также не определено. В примере использована ещё одна функция SQL Server DATEPART(), возвращающая целое значение определённой части даты (в нашем случае год). Замечания по вычислению выражений в SQL Коль мы уже добрались до выражений, немного прервёмся и скажем несколько слов о синтаксисе математических и логических операторов, правилах вычислений и преобразованиях типов.
Таблицы (окончание) База данных представляет собой набор связанных таблиц. Таблицы хранят некоторые факты, связи между таблицами устанавливают отношения между фактами. Благодаря связям из базы данных по одному известному факту можно извлечь все сопутствующие ему. Вспомним, что первичным ключом называется такое поле (или набор полей) таблицы, значения которого однозначно определяют запись в таблице. Такое поле содержит только уникальные значения. Внешним ключом называется такое поле (или набор полей) таблицы, значения которого полностью совпадают с некоторыми значениями первичного ключа какой-либо другой таблицы. Такое соответствие значений ключевых полей образует связь. Участвующие в связи таблицы называются: главной - содержащая поле первичного ключа, подчинённой - содержащая поле внешнего ключа. Связи бывают двух видов: в общем случае "один ко многим" ("1:М"), когда одной записи главной таблицы соответствует несколько записей подчинённой таблицы (в нескольких записях подчинённой таблицы в поле внешнего ключа содержится одинаковое значение, равное значению поля первичного ключа одной из записей главной таблицы); частным случаем является связь "один к одному" ("1:1"), причём подавляющее большинство СУБД такую связь в явном виде не поддерживает (её можно получить, используя свойство уникальности для поля внешнего ключа). Ещё известен тип связи "многие ко многим" ("М:М"), однако в СУБД он не поддерживается (лишь в крупных системах с мощными средствами автоматизации проектирования баз данных, бывает, встречаются связи такого типа, но в любом случае на уровне физического представления данных они заменяются на связи "1:М" через вспомогательные таблицы. Например, в нашей учебной базе данных (см. рисунок 1) есть три связи типа "М:М": между читателями (Readers) и книгами (Books), между книгами и произведениями (Works) и между произведениями и авторами (Authors). Для приведения этих связей к виду "1:М" определены вспомогательные таблицы: задолженности (Debts), сборники (Collections) и авторства (Athorships). Следует отметить, что вспомогательные таблицы не всегда являются "лишними". Примером тому служит таблица задолженностей (Debts), хранящая помимо фактов связей таблиц читателей (Readers) и книг (Books) дополнительные сведения. В качестве ключей лучше использовать маленькие по размеру значения полей (например, числа, короткие (в несколько символов) строки). Это экономит память, упрощает индексацию и поиск, отслеживание уникальности (самое главное). Кроме того, небольшие значения проще копировать при определении внешних ключей. Первоначально (в ранних СУБД) связи между таблицами явно (как особые объекты базы) не устанавливались. Используя механизм ключей пользователь сам вычислял связанные записи. В ходе эксплуатации таких баз в результате ошибок пользователей возникали нарушения целостности и непротиворечивости - важнейших требований, отличающих базу данных от хаоса. При модификации базы данных для поддержания её целостности пользователь должен был самостоятельно выполнять ряд действий:
Естественно, возникло желание (которое в современных многопользовательских СУБД с параллельной обработкой запросов является необходимым требованием) автоматизировать эти действия. Объект "связь" как раз и является тем сигналом для СУБД, который указывает на необходимость вышеописанных проверок при изменении данных в базе. В SQL через особое свойство поля, обозначаемое ключевым словом REFERENCES можно создать связь между данным полем, являющимся внешним ключом, и полем другой таблицы, являющимся первичным ключом. Например, для таблицы "Задолженности" (Debts) создадим связь с таблицей читатели.
В примере также использовано определение ON DELETE CASCADE, задающее особое поведение СУБД при работе со связью. Без такого определения всякая попытка удалить запись из главной таблицы при наличии связанных записей в подчинённой таблице будет блокирована. Указанное определение позволит удалить все подчинённые записи вместе с главной. В самом деле, если мы удаляем из базы данных читателя, зачем нам хранить связанные с ним задолженности? Они будут удалены автоматически. Удаление производится каскадно, т.е. если бы подчинённая таблица "Задолженности" (Debts) являлась бы главной для третьей таблицы, то и в третьй таблице удалились бы все связанные с удаляемыми задолженностями записи (если на той связи было бы установлено такое же определение). Для закрепления материала создадим таблицу "Произведения" (Works) с нужными связями.
И в заключении определения таблиц познакомимся с ограничениями. Ограничения - это объекты, ассоциированные с таблицей, задающие поведение СУБД при работе с записями таблицы. Фактически, со всеми ограничениями мы уже познакомились: первичный и внешний ключи, уникальные значения, значения по умолчанию и проверки - это всё ограничения. Их можно (и даже рекомендуется) записывать отдельно в конструкции CONSTRAINT. Описываются они наравне с полями при задании таблицы. Также к ним применимы операции ADD и DROP. Ещё одним свойством ограничений является то, что они могут быть применены к нескольким полям сразу. Описание поименованных ограничений отдельно от полей даёт ряд преимуществ при модификации таблиц. Например, для удаления внешнего ключа или уникального значения не нужно удалять поле со всеми данными в нём, достаточно удалить лишь ограничение. Каждое ограничение имеет собственное имя. Если ограничение задано не явно, а как свойство поля (как мы делали до сих пор), то ему автоматически назначается имя. Способ узнать имя такого ограничения зависит от СУБД. Так как имён имеющихся у нас ограничений мы не знаем, удалим таблицу "Задолженности" (Debts) целиком и пересоздаим её заново, описывая ограничения отдельно.
В примере для Access мы опустили все свойства, которые Access не поддерживает. Для ограничения внешнего ключа ключевым словосочетанием является FOREIGN KEY. Как видно из примера, ограничения можно задавать двумя способами: либо сразу за описанием поля (как определены значения по умолчанию), так и отдельно (как заданы ключи). Следует заметить, что значения по умолчаню отдельно заданы быть не могут, так как привязаны к одному конкретному полю (в отличие от проверок, уникальных значений и ключей). Теперь у нас таблица "Задолженности" (Debts) определена почти полностью - осталось лишь задать индекс. Приведём примеры изменения ограничений в уже созданных таблицах. Например, в созданную выше таблицу "Книги" (Books) добавим внешний ключ.
Ещё добавим проверку на заполнение кода книги.
В этом примере использована функция LEN(), возвращающая длину строки, хранящейся в поле. Завершая тему, приведём пример удаления ограничения. Удалим, значение по умолчанию длительности задолженности из таблицы "Задолженности" (Debts).
Задания для закрепления Задание одно: полностью сформировать нашу учебную базу данных (за исключением индексов). Для тех, кто использует Access, естественно, значения по умолчанию, вычисляемые поля и проверки с помощью встроенного SQL создать не удастся. Заключение статьи Не успели мы в этой статье рассмотреть индексы, как было обещано. Сделаем это в следующей. К настоящему моменту в нашем багаже знаний уже имеются все необходимые операции для создания набора связанных таблиц в базе данных, а также операции изменения и удаления таблиц и их объектов. Кроме индексов в следующей статье мы начнём изучать язык манипулирования данными, так как вводить понятия представлений, хранимых процедур, триггеров без языка запросов смысла не имеет. Мы не будем сильно углубляться в возможности применения языка запросов - эта тема будет раскрыта в отдельном цикле статей. Dimka, 15 сентября 2004 года |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |