| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
Проблемы несинхронизированного доступа к ресурсам (C) Dale, 02.11.2010 — 23.11.2010. В предыдущей статье мы весьма неформально рассмотрели проблемы, возникающие при конкуренции нескольких процессов за некий дефицитный ресурс, и некоторые способы решения этих проблем. Теперь пришла пора поговорить о механизмах взаимодействия процессов, а также о проблемах, возникающих при этом взаимодействии, и способах их решения. Как и прежде, мы постараемся сначала обсудить вопрос в наиболее общей форме, а затем учесть специфику встроенных систем на базе простых микроконтроллеров. Наиболее простая ситуация возникает, когда параллельные процессы в системе никак не взаимодействуют между собой. Они не подозревают о существовании друг друга, в идеале вообще не пересекаются, в крайнем случае конкурируют за общий ресурс. Простой (хотя и несколько надуманный) пример — две расчетные задачи, одновременно выполняемые на многопроцессорной машине и выводящие результат на принтер, плоттер или другое медленное (по отношению к скорости вычислений) устройство вывода (конечно же, на самом деле в современных операционных системах вывод на печать производится через спулер, поэтому ни одной задаче не придется ждать, пока принтер освободится). Картина усложняется, когда процессы должны взаимодействовать между собой. Это взаимодействие подразумевает обмен информацией. Иногда эта информация минимальна — фактически единственный бит, который сообщает о факте наступления события (например, освободилось место в кольцевом буфере). Иногда одного лишь знания о наступлении события мало, нужны дополнительные данные (например, завершено быстрое преобразование Фурье и можно забирать результат). Механизмы обмена данными могут быть очень простыми (общая для двух или более процессов область оперативной памяти) или сложными (каналы обмена сообщениями, сокеты, удаленные объекты, очереди сообщений и т.п.). Реальный пример... Рассмотрим такой пример. Наше приложение для микроконтроллера работает в качестве вольтметра-регистратора. Аналого-цифровой преобразователь (АЦП) в цикле измеряет входное напряжение. Когда цикл преобразования завершен, возникает прерывание. Программа обработки прерываний от АЦП помещает результат измерения в некоторую переменную. Программа каждую секунду считывает текущее значение напряжения из этой переменной, нормирует его и по интерфейсу RS232 отправляет на компьютер, который обрабатывает результаты измерений. Предположим, что наш АЦП имеет разрешение 10 бит (типичное значение для АЦП, встроенных в низкобюджетные микроконтроллеры). Для хранения этого значения нам потребуется 16-битная буферная переменная: младшие 8 бит результата будут храниться в младшем байте переменной, старшие 2 бита — в старшем байте переменной (рис. 1). В данном случае мы предполагаем, что выбранная нами архитектура поддерживает представление Little-endian, но это непринципиально и не нарушает общности наших рассуждений в целом. 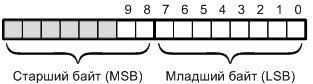 Рис. 1. 16-битная буферная переменная. Предположим также, что наш микроконтроллер имеет разрядность 8 бит (эти модели широко распространены, поскольку их низкая стоимость в сочетании с довольно высокой производительностью и развитой периферией делают их весьма привлекательными). Этот факт влечет два весьма важных, как мы впоследствии увидим, следствия:
Когда АЦП завершает очередной цикл измерения входного напряжения, он помещает результат в свои аппаратные регистры данных и инициирует прерывание. Это прерывание обслуживается соответствующей подпрограммой: Код: (Text) Подпрограмма обслуживания прерывания от АЦП Вход в подпрограмму прерывания Считать младший байт результата измерения Переслать его в младший байт буферной переменной Считать старший байт результата измерения Переслать его в старший байт буферной переменной Запустить следующий цикл измерения Выход из подпрограммы прерывания Процесс передачи данных на хост-компьютер работает полностью независимо от измерения. Он зациклен по следующему сценарию: Код: (Text) Процесс передачи данных на хост Начало цикла Считать младший байт данных из буферной переменной Считать старший байт данных из буферной переменной Нормализовать данные Передать данные по коммуникационному интерфейсу Выдержать паузу Конец цикла Казалось бы, данное простое решение полностью работоспособно. Процессам измерения и передачи данных не нужно согласовывать свои действия, поскольку они совершенно не мешают друг другу: один из них пишет данные в общую область памяти, другой считывает их оттуда. Однако не все так просто. ...и реальная проблема Рассмотрим ситуацию, когда напряжение медленно линейно нарастает. Впрочем, медленно — понятие растяжимое; в данном случае «медленно» означает, что оно остается неизменным в течение нескольких циклов передачи данных. Фраза «остается неизменным» тоже нуждается в конкретизации. Поскольку напряжение само по себе — значение непрерывное, а посредством оцифровки с помощью АЦП мы преобразуем его в дискретную величину, то в нашем случае «неизменное» означает «отличающееся от предыдущего значение на величину не более чем шаг квантования АЦП» (неидеальностью характеристик АЦП пренебрегаем, чтобы не усложнять ситуацию без необходимости). Если напряжение нарастает «медленно и линейно» (с учетом вышесказанного), настанет момент, когда младший байт результата измерения заполнится единицами, а старший — нулями: Код: 00000000 11111111 = 0x00FF Пройдет еще немного времени, напряжение подрастет на величину кванта АЦП, и произойдет перенос единицы из младшего байта в старший: Код: 00000000 11111111 = 0x00FF + 1 -------------------------- 00000001 00000000 = 0x0100 Вот тут-то нас и ожидает весьма неприятный сюрприз. Рассмотрим следующую последовательность событий:
Если хост, получающий результаты измерения, не просто регистрирует их, а принимает на их основе решения, последствия могут быть самыми плачевными: например, хост даст команду регулятору напряжения понизить напряжение вдвое или даже выполнит аварийное отключение потребителей. Аналогичная проблема может возникнуть при медленном линейном понижении напряжения в момент перехода от 0x0100 к 0x00FF. В этом случае, как несложно догадаться, результирующее значение будет 0x0000, что тоже весьма далеко от истины. Ищем причину Самое плохое в данной ситуации — это то, что ее практически невозможно диагностировать посредством отладки. Предположим, что мы получили жалобу от пользователя прибора, что он периодически выдает нулевые данные, когда на самом деле провалов напряжения не наблюдалось. Мы смотрим логику прибора и делаем предположение, что проблема кроется либо в измерении, либо в передаче данных. Мы пишем тест для измерения напряжения, который сигнализирует о нулевом результате с АЦП, подаем на вход ненулевое напряжение и неделю тестируем прибор на стенде. Ни единого нулевого результата нет — все говорит о том, что АЦП в порядке. Тогда мы тестируем подпрограмму передачи данных — подаем ей на вход различные ненулевые значения и ждем, когда на хост будет отправлен нуль. Опять тесты показывают, что все в порядке. Отчаявшись, мы пытаемся искать несуществующие проблемы в разъемах, блоке питания прибора, наводках и т.п. Все усилия тщетны — порознь все части прибора работают идеально, совместно же — дают сбой. Тогда мы переходим к комплексному тестированию прибора на стенде, подаем на вход напряжение с реостата, который постоянно крутим взад-вперед — и действительно видим, что изредка проскакивает ошибка. Но устойчиво воспроизвести ее не удается, последующие измерения дают нормальный результат. Где же кроется причина наших бед? Внимательно прочитав предыдущий сценарий, мы начинаем подозревать, что причина состоит в том, что прерывание от АЦП вклинилось между чтениями младшего и старшего байтов буферной переменной. Получается, что младший байт относится к результату предыдущего измерения, а старший — к результату следующего. Разумеется, это неправильно. Вот если бы мы могли гарантированно считать оба байта за один раз, не прерываясь на другие действия, которые могут повлиять на их значения, мы могли бы быть уверены, что оба они относятся к одному измерению. Итак, мы вплотную подошли к понятию атомарности, о котором уже было вскользь упомянуто в предыдущей статье. Атомарные операции Операция, которая выполняется как единое целое, называется атомарной операцией. После того, как некий процесс начал атомарную операцию, никакой другой процесс не может вмешаться в ее выполение таким образом, чтобы повлиять на ее результат. В предыдущем примере мы пришли к выводу, что считывание обоих байтов целочисленной переменной должно быть атомарным. То, какие операции являются атомарными, а какие нет, существенно зависит от аппаратной и программной среды. Поскольку мы рассматривали микроконтроллер с 8-битным ядром, он способен обрабатывать за одну операцию один байт данных (есть в его системе команд и 16-битные операции, но их немного, так что в общем случае не будет большой ошибкой считать, что любая операция обрабатывает один байт). Поскольку для пересылки 16-битового значения ему придется совершить две отдельные операции, то такая пересылка атомарной операцией сама по себе, без принятия дополнительных мер, не является. Процессоры с большей длиной слова, от 16 бит и выше, выполнят такую пересылку как единую операцию, поэтому она автоматически становится атомарной. Впрочем, это вовсе не означает, что наша проблема неатомарности чтения 16-битного целого не имеет решения на 8-разрядном ядре. Конечно, автоматически мы этого не добьемся, придется предпринимать дополнительные меры, чтобы сделать два подряд идущих считывания байта атомарной операцией. К счастью, это вполне решаемая задача. Поскольку мы не хотим, чтобы другой процесс мог вклиниться между частями атомарной операции, мы должны исключить саму принципиальную возможность такого вклинивания. В нашем случае такая возможность присутствует благодаря наличию механизма прерываний. Пожалуй, самое простое решение — это запретить прерывания вовсе на все время выполнения атомарной операции. Конечно, для системы реального времени основной показатель качества — это время реакции на событие, поэтому слишком злоупотреблять этим методом не следует. В нашем случае атомарная операция состоит из двух байтовых пересылок, каждая из которых занимает 1 такт в случае, если наш микроконтроллер принадлежит к семейству AVR. Обычно для типовых задач, решаемых при помощи МК, два такта — это немного, поэтому вариант с запретом прерываний подойдет в большинстве случаев. Однако не все атомарные операции столь коротки и быстры. Пример более сложных атомарных операций, знакомый большинству программистов, — это транзакции. Пример простой транзакции — это перевод безналичных денег со счета покупателя на счет продавца: какая сумма снята со счета покупателя, ровно такая же должна быть добавлена на счет продавца, в противном случае транзакция не должна состояться вовсе. Ситуация, когда некоторая сумма снята с одного счета, но не попала на другой, является совершенно недопустимой. Другие процессы не должны вмешиваться в ход транзакции. В данном случае простым запретом прерываний мы уже не сможем обойтись, поскольку, во-первых, транзакция может длиться достаточно долго, и прерывания могут просто потеряться, что может оказаться недопустимым; во-вторых, само проведение транзакции может оказаться невозможным в отсутствие прерываний от внешних устройств, задействованных в транзакции. Следовательно, наша модель процессов, которые ничего не знают друг о друге и взаимодействуют лишь через общую структуру в памяти, подходит лишь для простейших случаев. В общем случае нам потребуется какое-то средство, позволяющее процессам договориться между собой, то есть синхронизировать свои действия. Так мы подходим к еще одному важному понятию — синхронизации. Но о ней мы поговорим уже в следующей статье. Обсудить статью, высказать свои замечания и предложения зарегистрированные участники клуба могут здесь.
|
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |