| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
Введение в SQL - 2 Краткое содержание SQL - язык определения данных (продолжение) Всю эту статью мы посвятим различным действиям с небольшой базой данных. Для понимания значений употребляемых объектов базы данных, а также типов данных отсылаю читателя к первой статье цикла. Также будем полагать, что читающий эту статью умеет разбирать схемы данных и имеет представления о нормализации отношений в процессе проектирования (например, см. статьи Alf'а в этом же разделе статей). Помимо вышеуказанных знаний потребуется среда для самостоятельной работы по закреплению полученных знаний. Как уже говорилось во введении нашего цикла статей, для работы требуется иметь установленный Microsoft SQL Server. Процесс установки, чтобы не уклоняться от темы, мы здесь рассматривать не будем - с вопросами можно обратиться к автору на форум этого сайта. Помимо кода для SQL Server по возможности будет приводиться код для Microsoft Access. Рабочая база данных Объектом наших манипуляций будет база данных упрощённой библиотеки. Логическая модель в нотации Баркера представлена на рисунке 1. 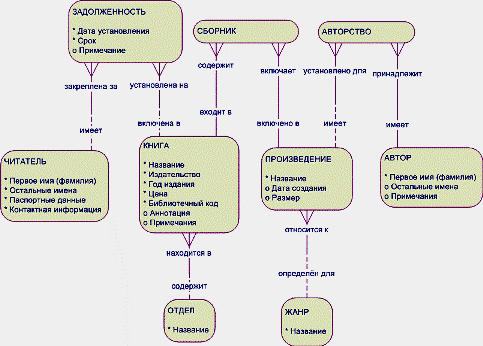 Рисунок 1 - Логическая статическая модель предметной области Условные обозначения: звёздочка - обязательный атрибут, кружок - необязательный атрибут, сплошная линия связи - обязательная связь, пунктирная линия связи - необязательная связь. По логической статической модели предметной области построена физическая модель базы данных, где уже введены искусственные ключи, указаны индексы, а названия переведены на английский - рисунок 2. 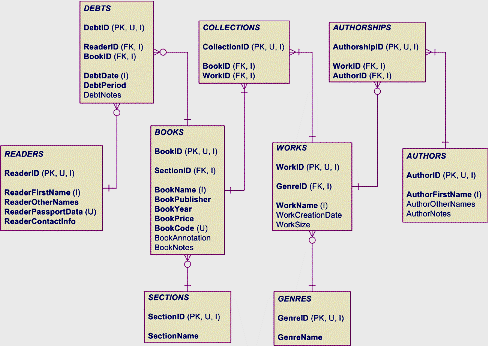 Рисунок 2 - Физическая модель базы данных Условные обозначения: PK - первичный ключ; FK - внешний ключ; I - индекс; U - уникальное значение; полужирным шрифтом выделены обязательные поля (не могущие быть пустыми - содержать NULL); на связях: чёрточка означает обязательное наличие записи, участвующей в связи; кружок - необязательное наличие (допустимо отсутствие связанных записей). На рисунке 2 обозначен ряд понятий, которые мы ещё не разбирали. Будем делать это ниже, по ходу изучения конструкций языка. Следует заметить, что представленная физическая модель является типичным инженерным решением, вызывающим праведный гнев теоретиков, однако выполнена согласно принятому в настоящее время подходу к построению баз данных - введены искусственные ключи, что обеспечивает "безболезненное" внесение изменений и дополнений в базу в процессе сопровождения. База данных Первой нашей задачей будет являться создание собственно базы данных. Вспомним (см. первую статью цикла), что база данных является контейнером, хранящим все относящиеся к ней объекты: таблицы, процедуры, представления, связи и т.д. База данных является пространством имён, отделяющим свои данные от данных другой базы. Кроме того, содержимое базы данных должно быть целостным и внутренне непротиворечивым. Дадим нашей базе данных уникальное (надеемся на это) в вашей СУБД название TrainingDB_1_SimpleLibrary. Тогда SQL-инструкция создания базы в простейшем случае выглядит так:
СУБД создаст базу данных, используя все параметры по умолчанию, создавая файлы базы данных в папке по умолчанию, установленной для СУБД. Так как различные СУБД имеют разную организацию хранения баз данных на дисках, разные параметры самих баз данных, инструкция CREATE DATABASE может иметь различные дополнения, специфичные для конкретной СУБД. Вышеприведённый краткий вариант является наиболее общим для всех. Примером создания базы данных для SQL Server, хранящейся в указанном файле (в SQL Server они имеют расширение MDF) будет инструкция:
Дополнительные параметры внутри инструкции создания базы данных следуют через запятую в скобках после ключевого слова ON. В данном примере NAME является логическим названием файла (для нужд SQL Server), а FILENAME - физическое полное наименование файла базы данных, где хранятся все объекты базы. Помимо файла данных автоматически создаётся файл лога, где ведётся журнал всех выполняемых над базой операций. Однако специфику SQL Server по хранению баз данных мы здесь рассматривать не будем, дабы не уклоняться от темы. Для удаления базы данных следует использовать инструкцию:
Замечания по синтаксису инструкций SQL Теперь, имея первые строчки на SQL, скажем пару слов о синтаксисе языка.
Операции: арифметика, работа со строками, преобразование типов и т.п. мы будем вводить по мере надобности в ходе дальнейшего изложения. Таблицы Вернёмся к нашей базе данных. После создания она уже содержит множество служебных объектов: пару десятков таблиц, представления, хранимые процедуры и пр., используемые сервером для управления базой. Теперь нам нужно добавить в неё наши таблицы. Начнём с самой простой - "Жанры". Прежде чем что-либо делать с базой данных, нужно сделать её текущей. Средствами SQL это выполняется очень простой командой:
Теперь текущей мы имеем нашу созданную базу данных. Структура всякой таблицы определяется колонками, из которых она состоит. Колонки эти называют полями. Каждое поле может хранить лишь определённый его типом набор данных. Например, числовое поле хранит только числа, текстовое - только текст. Наполняют таблицу строки. Каждая строка состоит из элементов, соответствующих полям таблицы, - значений полей. Создание таблицы "Жанры" с необходимыми полями осуществляется следующей командой:
Это простейший формат создания таблицы. В скобках через запятую перечисляются описания полей: сначала имя поля, потом его тип (см. первую статью цикла). Заметим, что создание чего бы то ни было в SQL начинается с ключевого слова CREATE. Созданная нами таблица имеет ряд недостатков. В частности, для задания связей между таблицами (которые мы опишем позднее) нам потребуется указать, какое из полей мы решили назначить первичным ключом. Первичным ключом называется такое поле (или набор полей), по значениям которого можно однозначно определить строчку таблицы. Это означает, что значения поля должны быть уникальными, т.е. ни в каких двух взятых строчках таблицы мы не должны найти одинаковые значения для поля первичного ключа. Чаще всего в каждую таблицу вводят специальное поле (в подавляющем большинстве имеющее целочисленный тип), которое в дальнейшем используется в качестве первичного ключа. Такое поле заполняется значением автоматически для каждой записи в момент её создания. В каждой таблице многие СУБД определяют счётчик, который автоматически увеличивается на 1 при добавлении новой записи, и значение этого счётчика записывается в качестве значения поля первичного ключа. Т.е. для первой созданной записи поле первичного ключа будет содержать число 1, для второй - 2 и т.д. Очевидно, что такой алгоритм работы гарантирует уникальность значения поля первичного ключа. Помимо первичного ключа нам нужно отразить в нашей таблице тот факт, что поля являются обязательными для заполнения. Поле необязательное для заполнения может ничего не содержать (быть в состоянии NULL). Обязательное для заполнение поле пустым быть не может, т.е. нельзя добавить в таблицу запись, не имеющую какого-нибудь значения обязательного для заполнения поля. В таблице "Жанры" все поля являются обязательными. Созданную таблицу можно изменять. Познакомимся с новой инструкцией:
Применённая инструкция: во-первых, изменяет таблицу, во-вторых, изменяет свойства поля таблицы. Ключевым словом в SQL, указывающим на изменение какой-нибудь структуры, является слово ALTER. В данном случае оно применено к полю таблицы и, как следствие, к таблице вообще. ALTER COLUMN изменяет описание поля: можно изменить тип, назначить новые или убрать старые свойства поля. В приведённой выше инструкции мы установили полю "Название" (GanreName) свойство NOT NULL, устанавливающее обязательность для заполнения значений этого поля. Установка обратного свойства NULL или пропуск этих свойств в описании поля (по умолчанию) делает поле необязательным для заполнения. Однако мы не изменили первое поле таблицы "Жанры". Это связано с ограничениями, наложенными на инструкцию ALTER COLUMN. Например, сейчас мы добавили полю "Название" (GanreName) то свойство, что оно не может быть пустым. Эта операция прошла успешно потому, что у нас в таблице нет никаких записей. Если бы записи были, причём ряд записей содержал бы в этом поле NULL, SQL Server отказался бы выполнить эту инструкцию, а Access выполнил бы, присвоив пустым записям в качестве значения пустые строчки. SQL Server не может сделать поле таблицы первичным ключом в инструкции ALTER COLUMN - запрет введён потому, что данное поле не имеет признака уникальности, т.е. не гарантируется, что первичный ключ будет являться таковым согласно своему определению, - база данных без такого запрета не может сохранить свою целостность и непротиворечивость. Чтобы сделать поле GanreID первичным ключом, нужно удалить старое поле (в этом случае, естественно, были бы потеряны данные, хранящиеся в этом поле, если бы они у нас там были), а затем добавить новое поле с нужными свойствами. Удаление поля GanreID таблицы "Жанры" реализует инструкция:
Добавление поля GanreID, обладающего нужными нам свойствами, в таблицу "Жанры" осуществляется следующей инструкцией:
Эта инструкция различается для Access и SQL Server - различаются типы данных. В Access есть специальный тип AUTOINCREMENT, реализующий вышеописанный алгоритм присвоения значений поля первичного ключа. В SQL Server такой алгоритм назначается специальной инструкцией identity(n,m), где n - число, начиная с которого будет работать счётчик, а m - число, на которое увеличивается счётчик при добавлении новой записи. Первичный ключ всегда уникален, всегда обязателен для заполнения и всегда проиндексирован (однако, в других СУБД индексирования может не быть), поэтому теперь можем сказать, что таблица "Жанры" (Ganres) нами полностью сформирована, согласно всем требованиям, предъявляемым к ней физической моделью (см. рисунок 2). Стоит заметить, что алгоритм поддержки уникальности для поля первичного ключа обязательным не является - можно установить любой тип данных, однако, в таком случае вам придётся самостоятельно обеспечивать уникальность значений этого поля в процессе эксплуатации базы данных. Для закрепления материала напишем инструкцию, создающую таблицу "Авторы":
Таблица "Авторы" пока что не имеет индекса поля "Первое имя (фамилия)" (AuthorFirstName), потом мы его создадим. Может так статься, что при создании базы данных, таблицы, поля и т.д. мы допустили опечатку. Может быть, через некоторое время нам понадобилось переименовать какой-нибудь объект. Как быть в таком случае? К сожалению, SQL не имеет специальных средств для решения этой проблемы. Единственным выходом является удаление старого объекта и последующее создание нового. Очень важно в этом случае не потерять хранящиеся в базе данные. Так как пока мы не разбирали инструкции языка манипулирования данными, то отложим подробное рассмотрение этого вопроса. Сейчас, пока наша база данных пуста, мы можем смело удалять старый объект и создавать новый с другим названием, но теми же свойствами. Следует отметить, что в SQL Server в системной базе данных master есть специальная хранимая процедура sp_rename, которая осуществляет переименование любого объекта базы данных, но работу с хранимыми процедурами мы будем разбирать много позже. Инструкция удаления таблицы проста и выглядит следующим образом, например, для таблицы "Жанры":
Как вы уже, наверное, заметили, инструкции по удалению объектов в SQL начинаются с ключевого слова DROP. Задания для закрепления
Пишите и исполняйте инструкции по одной, дабы не возникло каких-нибудь казусов, с которыми мы познакомимся, когда будем изучать хранимые процедуры. Познакомьтесь с системами помощи в Access и SQL Server - они для вас будут хорошими справочниками в будущем. Заключение статьи В этой статье мы освоили создание и удаление баз данных, создание, изменение и удаление таблиц, узнали, что такое поля, какие бывают у них свойства, что такое первичный ключ таблицы, и как его определить. В следующей статье мы продолжим работать с объектами базы данных и узнаем, что такое значения по умолчанию, проверки полей, индексы, связи и внешние ключи. Разумеется, узнаем, как их создавать, изменять и удалять. Dimka, 22 августа 2004 года |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |