| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
Введение в SQL - 4 Краткое содержание
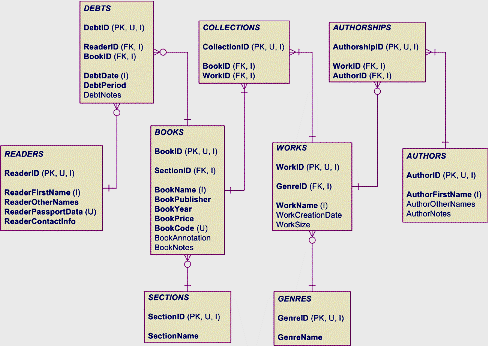
В этой статье мы завершим изучение операций над структурами баз данных и отложим изучение ранимых процедур до окончания знакомства с языком манипулирования данными. Даваемый материал основан на предыдущих статьях цикла. Также полагаем, что читатель имеет теоретическую подготовку в области реляционной алгебры (например, см. статьи Alf'а в этом же разделе статей). SQL - язык определения данных (продолжение) Для работы нам по-прежнему будут нужны Microsoft SQL Server (предпочтительно) или Microsoft Access. Рабочая база данных Продолжим работу по созданию и улучшению базы данных, которую мы начали в предыдущих статьях. Вспомним физическую модель базы нашей упрощённой библиотеки (см. рисунок 1).
Условные обозначения: PK - первичный ключ; FK - внешний ключ; I - индекс; U - уникальное значение; полужирным шрифтом выделены обязательные поля (не могущие быть пустыми - содержать NULL); на связях: чёрточка означает обязательное наличие записи, участвующей в связи; кружок - необязательное наличие (допустимо отсутствие связанных записей). Индексы В таблицах обычно записи хранятся в порядке их поступления, т.е. являются неупорядоченными по значениям полей. В таком случае единственной доступной стратегией поиска является последовательный перебор. Если в таблице хранится много тысяч или миллионов записей, последовательный поиск будет значительно понижать производительность СУБД. Чтобы ускорить поиск, нужно упорядочить значения в столбцах, по которым поиск осуществляется, чтобы СУБД могла воспользоваться более эффективными алгоритмами. Задачу упорядочивания в базе данных решают индексы. Индексом называется особый справочник значения поля (или нескольких полей одновременно), где в упорядоченном по значениям полей виде хранятся ссылки на записи. При использовании индексов на больших объёмах данных или при частых обращениях к базе данных наблюдается заметное (иногда даже многократное) ускорение работы СУБД. Означает ли это, что индексировать нужно все поля всех таблиц баз данных? Нет, не означает. За удобство, как известно, нужно платить. Платой служат дополнительные расходы памяти, время на загрузку индексов и время на операции поддержания индексов в актуальном состоянии. Это означает, что:
Таким образом, наиболее эффективное индексирование конкретной базы данных можно провести лишь после экспериментов в "полевых" условиях, т.е. в ходе эксплутации базы в реальной информационной системе с реальными данными (если есть такая потребность). Общие рекомендации проектирования индексов после создания схемы данных будут следующими:
Создадим индексы для таблицы "Задолженности" (Debts), поля "Дата задолженности" (DebtDate) и для таблицы "Книги" (Books) "Название" (BookName). (Не забудьте выбрать текущую базу командой USE).
Индекс является самостоятельным объектом базы данных, поэтому имеет имя. В скобках можно указывать несколько полей через запятую. Порядок задаётся ключевыми словами ASC (по возрастанию) и DESC (по убыванию), порядок определяется для каждого поля, а не для всех сразу. В индексах существует ограничение: поле не может быть включено в индекс дважды - поэтому для названия книги мы создали два отдельных индекса. Удалить индекс также не сложно. Например, удалим последний созданный индекс.
В ряде СУБД, например в старых версиях FoxPro, требовалось проводить ряд дополнительных операций с индексами, например, переиндексирование. В развитых СУБД в штатном режиме работы таких действий выполнять не нужно - это делается автоматически. Работа с индексами в развитых СУБД совершенно прозрачна и заметна лишь по повышению производительности. Все расширения по обслуживанию индексов лежат за рамками SQL, поэтому углубляться в этот вопрос мы не будем. В заключение остаётся заметить, что в SQL Server и некоторых других СУБД индексы бывают двух видов. В SQL Server они называются кластеризованными и некластеризованными. Выше мы обсуждали некластеризованные индексы, которые хранятся в отдельных справочниках. Таких индексов может быть достаточно много для одной таблицы. Кластеризованный индекс - это особая организация работы с таблицей, когда записи добавляются в таблицу в порядке, определяемом индексом. Т.е. кластеризованный индекс принудительно задаёт физический порядок записей, согласно индексу. Это обеспечивает масимальную производительность при операциях поиска по таблице по индексированному полю и не занимает дополнительной памяти на хранение самого индекса, однако по определению подобный индекс в таблице может быть только один. Для вставки новых записей в таблицах с кластеризованным индексом СУБД резервирует места, чтобы операция вставки не была слишком ресурсоёмкой (вне записи, лежащие ниже добавляемой приходилось бы физически сдвигать вниз). Если данных добавляется много, то СУБД проводит операцию резреживания таблицы (аналогично операции перестроения индекса) - это может занять заметное время. Заключение На этом мы прервём изучение языка определения данных SQL, так как дальнейшие объекты потребуют знания операций манипулирования данными. К настоящему моменту мы получили знания, как на SQL описать создание базы данных, а также менять и удалять структуры данных. SQL - язык манипулирования данными (начало) Для проработки изучаемого материала нам понадобится MS SQL Server (предпочтительно) или MS Access. Автор будет проверять публикуемый код в SQL Server 2000 и Access 2003. Рабочая база данных Для работы нам потребуется учебная база данных Northwind, которая входит в дистрибутивы как SQL Server, так и Access. Диаграмма данных, взятая из базы Northwind в SQL Server, представлена на рисунке 2.
[small]Условные обозначения: в таблице значок ключа на поле - первичный ключ; на связи значок ключа указывает на главную таблицу, значок бесконечности - на подчинённую.[/small] Зайдя в Query Analyzer, не забудьте выполнить команду:
Операции над данными В реляционных СУБД над данными можно выполнять четыре вида операций: поиск/выбор, вставка, обновление и удаление. Всякая операция в SQL выполняется над таблицей целиком, не над конкретными записями, а на над всей их совокупностью сразу - это нужно хорошо усвоить для правильного понимания работы команд языка манипулирования данными. Операция выбора Операция выбора в SQL реализуется командой SELECT - самой сложной по синтаксису командой в языке. SELECT многогранен и позволяет решать множество задач "за один приём". На мой взгляд наиболее продуктивным для понимания SELECT является подход, рассматривающий команду как композицию реляционных функций (SELECT - как язык функционального программирования). С помощью SELECT можно осуществлять: выбор аттрибутов (вертикальный фильтр), выбор записей (горизонтальный фильтр), декартово произведение отношений, объединение записей в одну с обобщением (агрегированием) данных (группировка), сортировку. Всё это следует умножить на возможность делать в запросе подзапросы. Далее мы будем разбирать все эти возможности, постепенно усложняя наши запросы, однако очень глубоко в возможности команды погружаться не будем. Сейчас нашей задачей является лишь освоение синтаксиса. Отработка навыков написания запросов в виде примеров, случаев из практики и уроков будет приведена позже, когда мы закончим изучение конструкций языка. Итак, если сказать кратко, SELECT осуществляет отображение (возможно, с преобразованием) из отношения или декартова произведения отношений в другое отношение, т.е. является реляционной функцией, определяемой пользователем. Переводя вышесказанное на язык баз данных, SELECT преобразует таблицу или ряд связанных таблиц в новую таблицу. Следовательно, простейшей формой SELECT будет отражение без преобразования некоего отношения (получение из базы данных одной таблицы целиком). Например,
После ключевого слова SELECT указываются поля, которые мы хотим видеть в таблице результата - это раздел вертикального фильтра. Звёздочка означает все поля таблицы. После раздела вертикального фильтра следует раздел исходных данных, начинающийся с ключевого слова FROM. В разделе исходных данных перечисляются таблицы, данные из которых берутся для запроса. После исполнения вышеприведённой команды мы получим на экране данные, хранящиеся в таблице Products рабочей базы данных Northwind. Выше я стрательно избегал слово "копирование" данных. Под термином "получить таблицу" результатов понимается осуществление операции извлечения данных из базы и передача куда-нибудь. В данном случае принимает данные Query Analyzer и отображает из на экране, а извлекает и передаёт SQL Server. Access является сам себе и источником и приёмником данных. Помимо вывода на экран, полученные данные (в виде таблицы) можно сохранять в переменных и выполнять с ними ряд действий по желанию программиста. Таким образом, таблица, полученная в результате SELECT, - это не таблица, хранящаяся в базе данных, а набор данных, переданных пользователю СУБД, однако такие данные чаще всего представляются в виде таблицы, поэтому в дальнейшем мы их также будем называть таблицей. Итак, под таблицами в разделе исходных данных запроса (секция FROM) мы будем понимать таблицы, хранящиеся в базе данных, а под таблицей результата - некий набор данных в табличном виде для отображения на экране или дальнейшей обработки. Псевдонимы имён таблиц Всякая таблица в секции FROM, причём не только физическая таблица на диске, но и подзапрос, может иметь псевдоним (alias), задающий её новое имя. Например,
В этом примере мы дали таблице Products псевдоним p, который можем использовать в дальнейшем (где и как именно - позже). Использование псевдонимов удобно при:
Вертикальный фильтр Вместо звёздочки можно указывать через запятую список полей таблицы, которые нам нужны, чтобы не передавать лишнюю информацию. Выбор полей совершенно необходим при операциях группировки и особых подзапросах. Например, нам требуется вывести на экран описание видов продукции (таблица Products), отсекая поля ключей, тогда мы запишем запрос следующим образом.
Обратите внимание, что перед именем поля отделённое точкой находится название таблицы, которой это поле принадлежит. Вообще, это название можно не писать, но только в том случае, если в разных таблицах, включённых в запрос, не встречаются одинаково называющиеся поля. Если такое случилось, то СУБД не будет знать, из какой таблицы подставить в результат значение поля, и сообщит об ошибке. Переименование полей Выводимые в результате запроса поля можно переименовать. Это делается:
Переименование полей выполняет ключевое слово AS в секции вертикального фильтра.
(В Access переименование имеющихся полей будет незаметным, т.к. для отображения на экране используется специальное "экранное" название поля, к SQL не относящееся.) Вычисляемые поля В качестве результата можно выводить не только значения полей, но и вычисляемые значения, описываемые в запросе в виде выражений, в которых могут быть использованы константы и значения полей таблиц (но не значения соседних вычисляемых полей). О вычислении выражений мы подробно говорили в предыдущей статье - там можно найти описание различных функций и операций над значениями разных типов данных. В результат запроса по таблице видов продукции (Products) мы можем включить поле, хранящее значения стоимости продукции на складе.
Если мы добавим ещё одно вычисляемое поле, то использовать для его вычисления значение CostInStock будет нельзя, так как оно будет определено только в результате. В этом случае придётся копировать всё выражение вычисления поля CostInStock в новое поле. В качестве вычисляемых значений также рассматриваются результаты агрегирующих функций (в SQL Server даже результаты подзапросов), но об этом позже. Первичный горизонтальный фильтр Первичный горизонтальный фильтр в запросе (секция WHERE) предназначен для выбора из всех записей исходных таблиц лишь тех, которые удовлетворяют условиию. В самой секции WHERE должно быть записано одно выражение (возможно, достаточно длинное), результат вычисления которого должен иметь логическое значение: истина или ложь. Если результат условия истинен, то запись пропускается для дальнейшей обработки, если ложен, то не пропускается. О вычислении выражений мы говорили в предыдущей статье цикла. Например, нам нужны лишь снятые с производства наименования продукции, тогда запрос будет выглядеть следующим образом:
В данном случае, в Access логическое значения поля Discontinued (снят с производства) непосредственно может быть использовано в условии, а в SQL Server тип данных bit считается разновидностью целочисленного типа, поэтому требуется явное сравнение с единицей. Разные операции сравнения можно соединять логическими операторами. Например, нам хочется найти не просто снятые с производства наименования продукции, а ещё и такие, цена упаковки которых от $100, тогда запрос будет выглядеть так:
В результате осталась лишь одна запись. Если же мы ещё более усилим условие и захотим, чтобы название продукции содержало слово "Uncle", то в результате мы не получим ни одной записи.
Обратите внимание, что в Access поиск по подстроке реализован не по стандарту SQL. Теперь можете убрать первые две части условия, и получите запись с названием продукции "Uncle Bob's Organic Dried Pears". Заключение статьи В этой статье мы завершили изучение команд SQL, позволяющих создавать объекты базы данных, относящиеся к хранению и первичной обработке данных, и перешли к изучению языка манипулирования данными. Начали знакомство с операцией поиска/выбора данных: познакомились с общей схемой запроса, вертикальным и первичным горизонтальным фильтрами. В следующей статье мы продолжим знакомство с операцией выбора данных. Dimka, 31 октября 2004 года |

| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |