| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
20 ловушек переноса Си++ - кода на 64-битную платформу. Андрей Карпов ООО "СиПроВер" Евгений Рыжков ООО "СиПроВер" Март 2007 Публикуется с разрешения автора. Оригинал статьи находится на сайте www.viva64.com. Содержание.
Аннотация. Рассмотрены программные ошибки, проявляющие себя при переносе Си++ - кода с 32-битных платформ на 64-битные платформы. Приведены примеры некорректного кода и способы его исправления. Перечислены методики и средства анализа кода, позволяющие диагностировать обсуждаемые ошибки. Введение. Вашему вниманию предлагается статья, посвященная переносу программного кода 32-битных приложений на 64-битные системы. Статья составлена для программистов, использующих Си++, но может быть полезна всем, кто сталкивается с переносом приложений на другие платформы. Нужно четко понимать, что новый класс ошибок, возникающий при написании 64-битных программ, - не просто еще несколько новых некорректных конструкций, среди тысяч других. Это означает неминуемые сложности, с которыми столкнутся разработчики любой развивающейся программы. Данная статья поможет подготовиться к этим трудностям и покажет пути их преодоления. Любая новая технология (как в программировании, так и в других областях) несет в себе, помимо преимуществ, также и некоторые ограничения или даже проблемы использования этой технологии. Точно такая же ситуация сложилась и в области разработки 64-битного программного обеспечения. Мы все знаем о том, что 64-битное программное обеспечение - это следующий этап развития информационных технологий. Однако немногие программисты пока реально столкнулись с нюансами этой области, а именно разработкой 64-битных программ. Мы не будем задерживаться на преимуществах, которые открывает перед программистами переход на 64-битную архитектуру. Данной тематике посвящено большое количество публикаций, и читателю не составит труда их найти. Целью этой статьи является подробный обзор тех проблем, с которыми может столкнуться разработчик 64-битных программ. В статье вы познакомитесь:
Приведенная информация позволит вам:
Для лучшего понимания изложенного материала в статье приводится много примеров. Знакомясь с ними, вы получите нечто большее, чем сумма отдельных частей. Вы откроете дверь в мир 64-битных систем. Для облегчения понимания дальнейшего текста вначале вспомним некоторые типы, с которыми мы можем столкнуться (см. таблица N1).
В тексте будет использоваться термин "memsize" тип. Под memsize-типом мы будем понимать любой простой целочисленный тип, способный хранить в себе указатель и меняющий свою размерность при изменении разрядности платформы с 32-бит на 64-бита. Примеры memsize-типов: size_t, ptrdiff_t, все указатели, intptr_t, INT_PTR, DWORD_PTR. Несколько слов следует уделить моделям данных, определяющим соотношения размеров фундаментальных типов для различных систем. В таблице N2 приведены модели данных, которые могут быть нам интересны.
По умолчанию в статье будет считаться, что перенос программ осуществляется с системы, имеющей модель данных ILP32, на системы с моделью данных LP64 или LLP64. И последнее: 64-битная модель в Linux (LP64) и Windows (LLP64) имеет различие только в размерности типа long. Поскольку это их единственное отличие, то для обобщения изложения мы будем избегать использования типов long, unsigned long, и будем использовать типы ptrdiff_t, size_t. Приступим к рассмотрению типовых ошибок, возникающих при переносе программ на 64-битную архитектуру. 1. Отключенные предупреждения. Во всех книгах, посвященных разработке качественного кода, рекомендуется выставлять уровень предупреждений, выдаваемых компилятором на как можно более высокий. Но на практике встречаются ситуации, когда для определенных частей проекта выставлен меньший уровень диагностики или вообще выключен. Обычно это очень старый код, который продолжает поддерживаться, но не модифицируется. Программисты, работающие в проекте, привыкли, что этот код работает, и закрывают глаза на его качество. Здесь и кроется опасность пропустить серьезные предупреждения компилятора при переносе программ на новую 64-битную систему. При переносе приложения следует обязательно включить предупреждения для всего проекта, помогающие проверить код на совместимость и внимательно проанализировать их. Это может существенно сэкономить время при отладке проекта на новой архитектуре. Если этого не сделать, то самые глупые и простые ошибки будут проявлять себя во всем своем многообразии. Вот простейший пример переполнения, который возникнет в 64-битной программе, если полностью игнорировать предупреждения: Код: (C++) unsigned char *array[50]; unsigned char size = sizeof(array); 32-bit system: sizeof(array) = 200 64-bit system: sizeof(array) = 400 2. Использование функций с переменным количеством аргументов. Классическим примером является некорректное использование функций printf, scanf и их разновидностей: Код: (C++) const char *invalidFormat = "%u"; size_t value = SIZE_MAX; printf(invalidFormat, value); Код: (C++) char buf[9]; sprintf(buf, "%p", pointer); В первом случае не учитывается, что тип size_t не эквивалентен типу unsigned на 64-битной платформе. Это приведет к выводу на печать некорректного результата, в случае если value > UINT_MAX. Во втором случае автор кода не учел, что размер указателя в будущем может составить более 32 бит. В результате на 64-битной архитектуре данный код приведет к переполнению буфера. Некорректное использование функций с перемененным количеством параметров является распространенной ошибкой на всех архитектурах, а не только 64-битных. Это связано с принципиальной опасностью использования данных конструкций языка Си++. Общепринятой практикой является отказ от них и использование безопасных методик программирования. Мы настоятельно рекомендуем модифицировать код и использовать безопасные методы. Например, можно заменить printf на cout, а sprintf на boost::format или std::stringstream. Если вы вынуждены поддерживать код, использующий функции типа sscanf, то в формате управляющих строк можно использовать специальные макросы, раскрывающиеся в необходимые модификаторы для различных систем. Пример: Код: (C++) // PR_SIZET on Win64 = "I" // PR_SIZET on Win32 = "" // PR_SIZET on Linux64 = "l" // ... size_t u; scanf("%" PR_SIZET "u", &u); 3. Магические константы. В некачественном коде часто встречаются магические числовые константы, наличие которых опасно само по себе. При миграции кода на 64-битную платформу эти константы могут сделать код неработоспособным, если участвуют в операциях вычисления адреса, размера объектов или в битовых операциях. В таблице N3 перечислены основные магические константы, которые могут влиять на работоспособность приложения на новой платформе.
Следует внимательно изучить код на предмет наличия магических констант и заменить их безопасными константами и выражениями. Для этого можно использовать оператор sizeof(), специальные значения из <limits.h>, <inttypes.h> и так далее. Приведем несколько ошибок, связанных с использованием магических констант. Самой распространенной является запись в виде числовых значений размеров типов: Код: (C++) size_t ArraySize = N * 4; intptr_t *Array = (intptr_t *)malloc(ArraySize); Код: (C++) size_t values[ARRAY_SIZE]; memset(values, ARRAY_SIZE * 4, 0); Код: (C++) size_t n, newexp; n = n >> (32 - newexp); Во всех случаях, предполагаем, что размер используемых типов всегда равен 4 байта. Исправление кода заключается в использовании оператора sizeof(): Код: (C++) size_t ArraySize = N * sizeof(intptr_t); intptr_t *Array = (intptr_t *)malloc(ArraySize); Код: (C++) size_t values[ARRAY_SIZE]; memset(values, ARRAY_SIZE * sizeof(size_t), 0); или Код: (C++) memset(values, sizeof(values), 0); //preferred alternative Код: (C++) size_t n, newexp; n = n >> (CHAR_BIT * sizeof(n) - newexp); Иногда может потребоваться специфическая константа. В качестве примера мы возьмем значение size_t, где все биты кроме 4 младших должны быть заполнены единицами. В 32-битной программе эта константа может быть объявлена следующим образом: Код: (C++) // constant '1111..110000' const size_t M = 0xFFFFFFF0u; Это некорректный код в случае 64-битной системы. Такие ошибки очень неприятны, так как запись магических констант может быть осуществлена различными способами и их поиск достаточно трудоемок. К сожалению, нет никаких других путей, кроме как найти и исправить этот код, используя директиву #ifdef или специальный макрос. Код: (C++) #ifdef _WIN64 #define CONST3264(a) (a##i64) #else #define CONST3264(a) (a) #endif const size_t M = ~CONST3264(0xFu); Иногда в качестве кода ошибки или другого специального маркера используют значение "-1", записывая его как "0xffffffff". На 64-битной платформе записанное выражение некорректно и следует явно использовать значение -1. Пример некорректного кода, использующего значение 0xffffffff как признак ошибки: Код: (C++) #define INVALID_RESULT (0xFFFFFFFFu) size_t MyStrLen(const char *str) { if (str == NULL) return INVALID_RESULT; ... return n; } size_t len = MyStrLen(str); if (len == (size_t)(-1)) ShowError(); На всякий случай уточним ваше понимание, чему с вашей точки зрения равно значение "(size_t)(-1)" на 64-битной платформе. Можно ошибиться, назвав значение 0x00000000FFFFFFFFu. Согласно правилам языка Си++ сначала значение -1 преобразуется в знаковый эквивалент большего типа, а затем в беззнаковое значение: Код: (C++) int a = -1; // 0xFFFFFFFFi32 ptrdiff_t b = a; // 0xFFFFFFFFFFFFFFFi64 size_t c = size_t(b); // 0xFFFFFFFFFFFFFFFui64 Таким образом, "(size_t)(-1)" на 64-битной архитектуре представляется значением 0xFFFFFFFFFFFFFFFui64, которое является максимальным значением для 64-битного типа size_t. Вернемся к ошибке с INVALID_RESULT. Использование константы 0xFFFFFFFFu приводит к невыполнению условия "len == (size_t)(-1)" в 64-битной программе. Наилучшее решение заключается в изменении кода так, чтобы специальных маркерных значений не требовалось. Если по какой-то причине Вы не можете от них отказаться или считаете нецелесообразным существенные правки кода, то просто используйте честное значение -1. Код: (C++) #define INVALID_RESULT (size_t(-1)) ... 4. Хранение в double целочисленных значений. Тип double, как правило, имеет размер 64-бита и совместим со стандартом IEEE-754 на 32-битных и 64-битных системах. Некоторые программисты используют тип double для хранения и работы с целочисленными типами: Код: (C++) size_t a = size_t(-1); double b = a; --a; --b; size_t c = b; // x86: a == c // x64: a != c Данный пример еще можно пытаться оправдывать на 32-битной системе, так как тип double имеет 52 значащих бит и способен без потерь хранить 32-битное целое значение. Но при попытке сохранить в double 64-битное целое число точное значение может быть потеряно (см. рисунок 1). 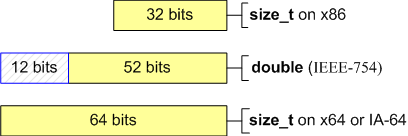 Рисунок 1. Количество значащих битов в типах size_t и double. Возможно, приближенное значение вполне применимо в вашей программе, но на всякий случай хочется сделать предупреждение о потенциальных эффектах на новой архитектуре. И в любом случае не рекомендуется смешивать целочисленную арифметику и арифметику с плавающей точкой. 5. Операции сдвига. Операции сдвига при невнимательном использовании могут принести много неприятностей во время перехода от 32-битной к 64-битной системе. Начнем с примера функции, выставляющей в переменной типа memsize, указанный вами бит в 1: Код: (C++) ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) { ptrdiff_t mask = 1 << bitNum; return value | mask; } Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять биты с номерами от 0 до 31. После переноса программы на 64-битную платформу возникнет необходимость выставлять биты от 0 до 63. Как вы думаете, какое значение вернет следующий вызов функции SetBitN(0, 32)? Если вы думаете, что 0x100000000, то авторы рады, что не зря подготовили эту статью. Вы получите 0. Обратите внимание, что "1" имеет тип int и при сдвиге на 32 позиции произойдет переполнение, как показано на рисунке 2. 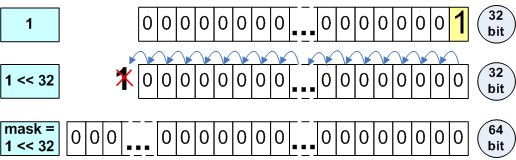 Рисунок 2. Вычисление выражения "ptrdiff_t mask = 1 << bitNum". Для исправления кода необходимо сделать константу "1" того же типа, что и переменная mask. Код: (C++) ptrdiff_t mask = ptrdiff_t(1) << bitNum; или Код: (C++) ptrdiff_t mask = CONST3264(1) << bitNum; Еще один вопрос. Чему будет равен результат вызова неисправленной функции SetBitN(0, 31)? Правильный ответ 0xffffffff80000000. Результатом выражения 1 << 31 является отрицательное число -2147483648. Это число представляется в 64-битной целой переменной как 0xffffffff80000000. Следует помнить и учитывать эффекты сдвига значений различных типов. Для лучшего понимания и наглядности изложенной информации в таблице N4 приведен ряд интересных выражений со сдвигами в 64-битной системе.
6. Упаковка указателей. Большое количество ошибок при мигрировании на 64-битные системы связано с изменением размера указателя по отношению к размеру обычных целых. В среде с моделью данных ILP32 обычные целые и указатели имеют одинаковый размер. К сожалению, 32-битный код повсеместно опирается на это предположение. Указатели часто приводятся к int, unsigned int и другим неподходящим типам для выполнения адресных расчетов. Следует четко помнить, что для целочисленного представления указателей следует использовать только memsize типы. Предпочтение, на наш взгляд, следует отдавать типу uintptr_t, так как он лучше выражает намерения и делает код более переносимым, предохраняя его от изменений в будущем. Рассмотрим два небольших примера. Код: (C++) char *p; p = (char *) ((int)p & PAGEOFFSET); Код: (C++) DWORD tmp = (DWORD)malloc(ArraySize); ... int *ptr = (int *)tmp; Оба примера не учитывают, что размер указателя может отличаться от 32 бит. Используется явное приведение типа, отбрасывающее старшие биты в указателе, что является явной ошибкой на 64-битной системе. Исправленные варианты, использующие для упаковки указателей целочисленные memsize типы (intptr_t и DWORD_PTR), приведены ниже: Код: (C++) char *p; p = (char *) ((intptr_t)p & PAGEOFFSET); Код: (C++) DWORD_PTR tmp = (DWORD_PTR)malloc(ArraySize); ... int *ptr = (int *)tmp; Опасность двух рассмотренных примеров в том, что сбой в программе может быть обнаружен спустя очень большой промежуток времени. Программа может совершенно корректно работать с небольшим объемом данных на 64-битной системе, пока обрабатываемые адреса находятся в пространстве первых четырех гигабайт памяти. А затем, при запуске программы на больших производственных задачах, произойдет выделение памяти за пределами этой области. Рассмотренный в примерах код, обрабатывая указатель на объект вне данной области, приведет к неопределенному поведению программы. Следующий приведенный код не будет таиться и проявит себя при первом выполнении: Код: (C++) void GetBufferAddr(void **retPtr) { ... // Access violation on 64-bit system *retPtr = p; } unsigned bufAddress; GetBufferAddr((void **)&bufAddress); Исправление также заключается в выборе типа, способного вмещать в себя указатель. Код: (C++) uintptr_t bufAddress; GetBufferAddr((void **)&bufAddress); //OK Бывают ситуации, когда упаковка указателя в 32-битный тип просто необходима. В основном такие ситуации возникают при необходимости работы со старыми API функциями. Для таких случаев следует прибегнуть к специальным функциям, таким как LongToIntPtr, PtrToUlong и так далее. Резюмируя, хочется заметить, что плохим стилем будет упаковка указателя в типы, всегда равные 64-битам. Показанный ниже код вновь придется исправлять с приходом 128-битных систем: Код: (C++) PVOID p; // Bad style. The 128-bit time will come. __int64 n = __int64(p); p = PVOID(n); 7. Memsize-типы в объединениях. Особенностью объединения является то, что для всех элементов - членов объединения выделяется одна и та же область памяти, то есть они перекрываются. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат не был бессмысленным. Следует внимательно отнестись к объединениям, имеющим в своем составе указатели и другие члены типа memsize. Когда возникает необходимость работать с указателем как с целым числом, иногда удобно воспользоваться объединением, как показано в примере, и работать с числовым представлением типа без использования явных приведений: Код: (C++) union PtrNumUnion { char *m_p; unsigned m_n; } u; u.m_p = str; u.m_n += delta; Данный код корректен на 32-битных системах и некорректен на 64-битных. Изменяя член m_n на 64-битной системе, мы работаем только с частью указателя m_p. Следует использовать тип, который будет соответствовать размеру указателя: Код: (C++) union PtrNumUnion { char *m_p; size_t m_n; //type fixed } u; Другое частое использование объединения заключается в представлении одного члена, набором других более мелких. Например, нам может потребоваться разбить значение типа size_t на байты для реализации табличного алгоритма подсчета количества нулевых битов в байте: Код: (C++) union SizetToBytesUnion { size_t value; struct { unsigned char b0, b1, b2, b3; } bytes; } u; SizetToBytesUnion u; u.value = value; size_t zeroBitsN = TranslateTable[u.bytes.b0] + TranslateTable[u.bytes.b1] + TranslateTable[u.bytes.b2] + TranslateTable[u.bytes.b3]; Здесь допущена принципиальная алгоритмическая ошибка, заключающаяся в предположении, что тип size_t состоит из 4 байт. Возможность автоматического поиска алгоритмических ошибок пока вряд ли возможна, но мы можем осуществить поиск всех объединений и проверить наличие в них memsize-типов. Найдя такое объединение, мы можем обнаружить алгоритмическую ошибку и переписать код следующим образом. Код: (C++) union SizetToBytesUnion { size_t value; unsigned char bytes[sizeof(value)]; } u; SizetToBytesUnion u; u.value = value; size_t zeroBitsN = 0; for (size_t i = 0; i != sizeof(bytes); ++i) zeroBitsN += TranslateTable[bytes[i]]; 8. Изменение типа массива. Иногда в программах необходимо (или просто удобно) представлять элементы массива в виде элементов другого типа. Опасное и безопасное приведение типов представлено в следующем коде: Код: (C++) int array[4] = { 1, 2, 3, 4 }; enum ENumbers { ZERO, ONE, TWO, THREE, FOUR }; //safe cast (for MSVC2005) ENumbers *enumPtr = (ENumbers *)(array); cout << enumPtr[1] << " "; //unsafe cast size_t *sizetPtr = (size_t *)(array); cout << sizetPtr[1] << endl; //Output on 32-bit system: 2 2 //Output on 64 bit system: 2 17179869187 Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов size_t и int совпадают, и мы видим вывод "2 2". На 64-битной системе мы получили в выводе "2 17179869187", так как именно значение 17179869187 находится в 1-ом элементе массива sizetPtr (см. рисунок 3). В некоторых случаях именно такое поведение и бывает нужно, но обычно это является ошибкой. 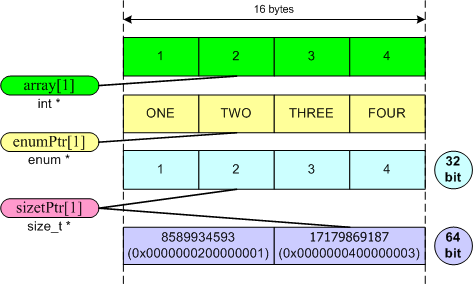 Рисунок 3. Расположение элементов массивов в памяти. Исправление описанной ситуации заключается в отказе от опасных приведений типов путем модернизации программы. Другим вариантом является создание нового массива и копирование в него значений из исходного массива. 9. Виртуальные функции с аргументами типа memsize. Если у вас в программе имеются большие иерархии наследования классов с виртуальными функциями, то существует вероятность использования по невнимательности аргументов различных типов, но которые фактически совпадают на 32-битной системе. Например, в базовом классе вы используете в качестве аргумента виртуальной функции тип size_t, а в наследнике - тип unsigned. Соответственно, на 64-битной системе этот код будет некорректен. Такая ошибка не обязательно кроется в сложных иерархиях наследования, и вот один из примеров: Код: (C++) сlass CWinApp { ... virtual void WinHelp(DWORD_PTR dwData, UINT nCmd); }; class CSampleApp : public CWinApp { ... virtual void WinHelp(DWORD dwData, UINT nCmd); }; Проследим жизненный цикл разработки некоторого приложения. Пусть первоначально оно разрабатывалось под Microsoft Visual C++ 6.0., когда функция WinHelp в классе CWinApp имела следующий прототип: Код: (C++) virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT); Совершенно верно было осуществить перекрытие виртуальной функции в классе CSampleApp, как показано в примере. Затем проект был перенесен в Microsoft Visual C++ 2005, где прототип функции в классе CWinApp претерпел изменения, заключающиеся в смене типа DWORD на тип DWORD_PTR. На 32-битной системе программа продолжит совершенно корректно работать, так как здесь типы DWORD и DWORD_PTR совпадают. Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код. Исправление заключается в использовании одинаковых типов в соответствующих виртуальных функциях. Код: (C++) сlass CSampleApp : public CWinApp { ... virtual void WinHelp(DWORD_PTR dwData, UINT nCmd); }; 10. Сериализация и обмен данными. Важным элементом переноса программного решения на новую платформу является преемственность к существующим протоколам обмена данных. Необходимо обеспечить чтение существующих форматов проектов, осуществлять обмен данными между 32-битными и 64-битными процессами и так далее. В основном ошибки данного рода заключаются в сериализации memsize-типов и операциях обмена данными с их использованием: Код: (C++) size_t PixelCount; fread(&PixelCount, sizeof(PixelCount), 1, inFile); Код: (C++) __int32 value_1; SSIZE_T value_2; inputStream >> value_1 >> value_2; Код: (C++) time_t time; PackToBuffer(MemoryBuf, &time, sizeof(time)); Во всех приведенных примерах имеются ошибки двух видов: использование типов непостоянной размерности в бинарных интерфейсах и игнорирование порядка байт. Использование типов непостоянной размерности. Недопустимо использование типов, которые меняют свой размер в зависимости от среды разработки, в бинарных интерфейсах обмена данными. В языке Си++ все типы не имеют четкого размера и, следовательно, их все невозможно использовать для этих целей. Поэтому создатели средств разработки и сами программисты создают типы данных, имеющие строгий размер, такие как __int8, __int16, INT32, word64 и так далее. Использование подобных типов обеспечивает переносимость данных между программами на различных платформах, хотя и требует дополнительных усилий. Три показанных примера написаны неаккуратно, что даст о себе знать при смене разрядности некоторых типов данных с 32-бит до 64-бит. Учитывая необходимость поддержки старых форматов данных, исправление может выглядеть следующим образом: Код: (C++) size_t PixelCount; __uint32 tmp; fread(&tmp, sizeof(tmp), 1, inFile); PixelCount = static_cast<size_t>(tmp); Код: (C++) __int32 value_1; __int32 value_2; inputStream >> value_1 >> value_2; Код: (C++) time_t time; __uint32 tmp = static_cast<__uint32>(time); PackToBuffer(MemoryBuf, &tmp, sizeof(tmp)); Но приведенный вариант исправления может являться не лучшим. При переходе на 64-битную систему программа может обрабатывать большее количество данных, и использование в данных 32-битных типов может стать существенным препятствием. В таком случае, можно оставить старый код для совместимости со старым форматом данных, исправив некорректные типы. И реализовать новый бинарный формат данных уже с учетом допущенных ошибок. Еще одним вариантом может стать отказ от бинарных форматов и переход на текстовый формат или другие форматы, предоставляемые различными библиотеками. Игнорирование порядка байт (byte order). Даже после внесения исправлений, касающихся размеров типа, вы можете столкнуться с несовместимостью бинарных форматов. Причина кроется в ином представлении данных. Наиболее часто это связано с другой последовательностью байт. Порядок байт - метод записи байтов многобайтовых чисел (см. также рисунок 4). Порядок от младшего к старшему (англ. little-endian) - запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами. Порядок от старшего к младшему (англ. big-endian): запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP. Поэтому порядок байтов от старшего к младшему часто называют сетевым порядком байтов (англ. network byte order). Этот порядок байт используется процессорами Motorola 68000, SPARC.  Рисунок 4. Порядок байт в 64-битном типе на little-endian и big-endian системах. Разрабатывая бинарный интерфейс или формат данных, следует помнить о последовательности байт. А если 64-битная система, на которую вы переносите 32-битное приложение, имеет иную последовательность байт, то вы просто будете вынуждены учесть это в своем коде. Для преобразования между сетевым порядком байт (big-endian) и порядком байт (little-endian), можно использовать функции htonl(), htons(), bswap_64, и так далее. (Вторая часть статьи.) |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |