| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
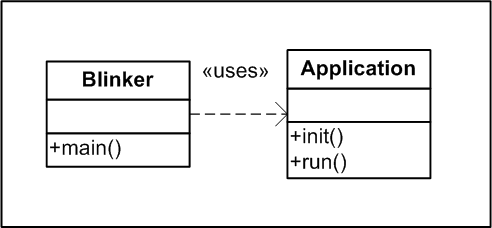
«Hello World!» в embedded-исполнении. Часть 3 © Dale, 04.11.2011 — 05.11.2011. Начало: часть 1, часть 2. Оглавление Модуль Application В предыдущей статье мы остановились на том, что решили вынести функции инициализации и главного цикла приложения в отдельный модуль. Этим сейчас и займемся. Автоматизируем создание поддиректории модуля Сначала нужно подготовить поддиректорию для этого модуля, а в ней создать поддиректории для интерфейса, исходных текстов, объектных модулей, тестов... Впрочем, я уже повторяюсь. Стоп. Мы уже один раз проделывали эти действия для главного модуля программы. Кроме того, наша программа, хоть и небольшая, вряд ли ограничится двумя этими модулями. Следовательно, мы не раз повторим подобные действия. А это значит, что их необходимо автоматизировать. Во-первых, мы сэкономим немного времени. Во-вторых, что важнее, мы избежим ошибок, которые нередки при выполнении рутинной работы (опечатки, забытые поддиректории и т.п.). В-третьих, такая работа, хоть она и не требует выдающихся умственных усилий, отвлекает от мыслей о главном — архитектуре нашего приложения. Поэтому потратим несколько минут и напишем небольшой скрипт для создания поддиректории модуля: Код: (DOS) CreateModule.bat :: директория для модуля mkdir %1 :: поддиректория для интерфейса mkdir %1\include :: поддиректория для исходных текстов mkdir %1\src :: поддиректория для объектных файлов инструментальной системы mkdir %1\obj\PC :: поддиректория для тестов mkdir %1\test Разместим его в поддиректории Software, из которой «растут» все модули проекта. Теперь достаточно набрать в командной строке: > CreateModule.bat Application , и мы получим желаемое: E:\Projects\Shelek\Blinker\Software>mkdir Application E:\Projects\Shelek\Blinker\Software>mkdir Application\include E:\Projects\Shelek\Blinker\Software>mkdir Application\src E:\Projects\Shelek\Blinker\Software>mkdir Application\obj\PC E:\Projects\Shelek\Blinker\Software>mkdir Application\test Все готово, можно наполнять модуль содержимым. Впрочем, раз уж мы решили минимизировать малопродуктивный и чреватый ошибками ручной труд, сделаем еще шаг в этом направлении. Автоматизируем создание заготовки модуля Прежде всего в поддиректорию vendor скопируем нашу старую знакомую Unity. Читатели, ознакомившиеся с предыдущими статьями, уже знают, где ее взять (а возможно, уже и успели обзавестись). Затем пишем скрипт: Код: (DOS) GenMod.bat ruby vendor\unity\auto\generate_module.rb -i"%1/include" -s"%1/src" -t"%1/test" %2 %3 Выполняем: GenMod.bat Application Application Результат: E:\Projects\Shelek\Blinker\Software>ruby vendor\unity\auto\generate_module.rb -i"Application/include" -s"Application/src" -t"Application/test" Application File Application/src/Application.c created File Application/include/Application.h created File Application/test/TestApplication.c created Generate Complete Посмотрим, что создал генератор модулей. Код: (C) Application.h #ifndef _APPLICATION_H #define _APPLICATION_H #endif // _APPLICATION_H Код: (C) Application.c #include "Application.h" Код: (C) TestApplication.c #include "unity.h" #include "Application.h" void setUp(void) { } void tearDown(void) { } void test_Application_NeedToImplement(void) { TEST_IGNORE(); } Пока что ничего неожиданного, нечто подобное мы уже видели при знакомстве с Unity. Теперь мы можем наконец реализовать свои намерения по переносу функций инициализации и главного цикла приложения в модуль Application: Рефакторинг Код: (C) Application.h #ifndef _APPLICATION_H #define _APPLICATION_H void Application_init(void); void Application_run(void); #endif // _APPLICATION_H Ограничимся пока пустышками вместо реальных функций, только чтобы пройти компиляцию без ошибок: Код: (C) Application.c #include "Application.h" void Application_init(void) { } void Application_run(void) { } Чтобы скомпилировать модуль, нам понадобится Makefile: Код: (Text) "Makefile" # Подставьте здесь команду для вызова вашего компилятора C CC=mingw32-gcc CPPFLAGS=-I include .DEFAULT : obj\PC\Application.o obj\PC\Application.o : src\Application.c include\Application.h $(COMPILE.c) -o obj\PC\Application.o src\Application.c .PHONY : clean clean : del /q obj\PC\*.o Он представляет собой почти точную копию Makefile для главного модуля программы — я попросту скопировал его в новое место и немного подкорректировал. Конечно же, это очень плохой стиль программирования, который ведет к множеству копий одного фрагмента кода и, как следствие, к трудностям модификации и сопровождения кода в целом, а значит, к низкому качеству продукта. Например, вы решили перейти с MinGW на Cygwin (или наоборот, не имеет значения). Попробуйте вручную синхронно модифицировать значения переменной CC в полусотне make-файлов, раскиданных по разным поддиректориям проекта. Поэтому мы непременно вернемся к этой проблеме чуть позже. Впрочем, в то же время не следует забывать, чем чревата преждевременная оптимизация. Выберем золотую середину: сначала делаем, как проще (пусть даже это выглядит безобразно), добиваемся, чтобы это правильно заработало, а затем подвергаем рефакторингу до безупречного состояния. Сначала убеждаемся, что наш Makefile работает: создаем с его помощью obj\PC\Application.o, затем выполняем очистку поддиректории модуля командой make clean. Затем интегрируем наш модуль с главной программой, добиваясь сборки без сообщений об ошибках: Код: (C) Blinker.c #include "Application.h" int main() { Application_init(); for (;;) Application_run(); } Код: (Text) "Makefile" # Подставьте здесь команду для вызова вашего компилятора C CC=mingw32-gcc APPLICATION_DIR=..\Application CPPFLAGS=-I $(APPLICATION_DIR)\include .DEFAULT : Blinker.exe Blinker.exe : obj\PC\Blinker.o ..\Application\obj\PC\Application.o $(LINK.c) -o Blinker.exe obj\PC\Blinker.o ..\Application\obj\PC\Application.o obj\PC\Blinker.o : src\Blinker.c ..\Application\include\Application.h $(COMPILE.c) -o obj\PC\Blinker.o src\Blinker.c ..\Application\obj\PC\Application.o : ..\Application\src\Application.c ..\Application\include\Application.h $(MAKE) -C ..\Application .PHONY : clean clean : del /q obj\PC\*.* del /q Blinker.exe .PHONY : depend depend : $(CC) $(CPPFLAGS) -M src\Blinker.c (помимо новых зависимостей от модуля Application, я добавил еще цель depend для упрощения отслеживания зависимостей между модулями). Убеждаемся, что наш проект собирается без ошибок (разумеется, запускать полученную в результате программу не имеет смысла, она попросту зациклится). Замечания по архитектуре проекта Перед тем, как двигаться дальше, оценим архитектуру нашего творения. Вот как она выглядит в представлении UML:
Приверженцы «чистого кода» поставят плохую оценку такой архитектуре. Действительно, в ней модуль более высокого уровня Blinker «знает» все о модуле более низкого уровня Application. В свою очередь, модуль Application не имеет понятия о существовании модуля Blinker; он всего лишь предлагает свой сервис (описанный в заголовочном файле Application.h) всем желающим им воспользоваться. Направление зависимости от верхнего уровня к нижнему чревато тем, что изменение, внесенное на нижнем (вспомогательном) уровне, затрагивает все зависимые уровни вплоть до самого верхнего. Хорошего в этом мало. Хорошая архитектура предполагает противоположный подход: модули верхних уровней не должны зависеть от модулей нижних уровней. Модули нижних, наоборот, должны зависеть от модулей верхних, ведь единственное их назначение — обслуживать модули верхних уровней. В этом случае можно свободно изменять реализацию вспомогательных модулей на нижних уровнях, не рискуя затронуть архитектуру приложения в целом. Обычно привести архитектуру в порядок можно применением инверсии зависимостей. Это хороший метод; однако в нашем случае применить его было бы нелегко. Инверсия зависимостей в классическом варианте реализуется посредством широкого использования интерфейсов. Поэтому пользоваться ей весьма просто, когда вы пишете на одном из языков, явно поддерживающих концепцию интерфейса. При использовании языка C мы можем лишь имитировать объектно-ориентированное программирование с переменным успехом. Так, мы имитируем интерфейс модуля посредством специально выделенного для этого заголовочного файла. Отделение же файла заголовка от файла реализации и перенос его на более высокий уровень внесет в нашем случае только путаницу. Поэтому придется пойти на компромисс и отказаться от инверсии зависимостей, как бы нам этого ни хотелось. Загрузить текущее состояние проекта можно здесь. Анализ предметной области До сих пор мы говорили об архитектуре встроенного приложения в самом общем виде, без учета назначения приложения. Пора начинать заполнение наших «пустышек» реальным проблемно-ориентированным кодом. Но сначала нужно разобраться с сутью самой задачи. В реальных проектах фаза анализа сама по себе столь трудоемка, объемна и сложна, что ей следовало бы посвятить минимум десяток-другой аналогичных статей. Впрочем, мы специально выбрали для обучения вырожденную задачу, которую можно свести к единственному требованию: включать светодиод на 0.5 секунды каждые 2 секунды.
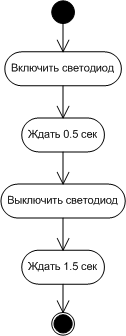
Эта задача как раз под силу методу Application.run(). Его работа сводится к последовательности действий:
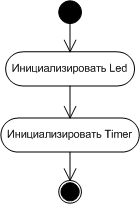
Для наглядности зафиксируем эту нехитрую процедуру в виде соответствующей диаграммы UML (рис. 2), которую подошьем к пакету проектной документации. Что необходимо для работы этой процедуры? Прежде всего, очевидно, нам понадобится средство для включения/выключения светодиода. Этим займется модуль Led. Затем нам необходимо средство для отслеживания временных интервалов. В реализации GNU C для платформы AVR ATmega есть несколько библиотечных функций, которые выдерживают заданную паузу. К сожалению, они используют программную задержку, выполняя пустой цикл заданное число раз. С этим можно было бы смириться на первых порах, пока у микроконтроллера нет других задач; однако неразумно было бы расходовать все ресурсы на такую примитивную задачу, когда параллельно можно было бы заняться чем-то более полезным. Поэтому наше решение должно позволить впоследствии расширение до полноценного варианта с использованием аппаратного таймера и обработки прерываний от него. И еще одна важная деталь. Для того, чтобы модуль управления свечением светодиода мог работать, он должен сначала соответствующим образом подготовить (инициализировать) необходимые для этого аппаратные средства (какие именно — уточним позже, пока нам важен сам принцип). То же относится и к модулю таймера: аппаратные средства таймера также нуждаются в предварительной инициализации до использования. Этой задачей займется метод Application.init() (рис. 3).
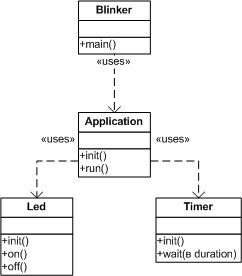
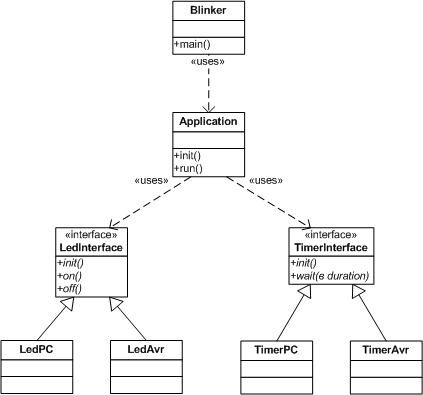
Крайне неразумно было бы заниматься столь низкоуровневыми задачами, как инициализация оборудования, непосредственно в модуле Application. Прежде всего, такое решение сильно привязано к конкретной реализации оборудования и поэтому крайне негибко. Кроме того, в нем перемешиваются совершенно разные логические уровни: бизнес-логика (что и в какой последовательности включать) и уровень оборудования (как именно включать). Очевидно, что модуль Application должен делегировать подобные задачи специализированным низкоуровневым модулям, в которых сосредоточены все детали конкретной реализации. Эти соображения приводят нас к такой архитектуре приложения (рис. 4):
Устроит ли нас такая архитектура? Пожалуй, устроила бы, если бы мы согласились на последующую отладку на целевой системе «методом тыка». Но поскольку мы с самого начала решили отказаться от такого подхода, нам потребуется привести архитектуру к виду, более пригодному для тестирования. Прежде всего очевидно, что, если мы намереваемся выполнить максимум работы на инструментальной системе, нам потребуются средства для реализации низкоуровневых модулей в ее среде. Но аппаратные средства микроконтроллера AVR ATmega весьма отличаются от аппаратных средств IBM PC, не говоря уже об различиях выполнения программ на «голом железе» и в среде ОС MS Windows. Совместить столь отличающиеся реализации мы можем лишь с использованием абстракций. Заменим конкретные модули интерфейсами (рис. 5):
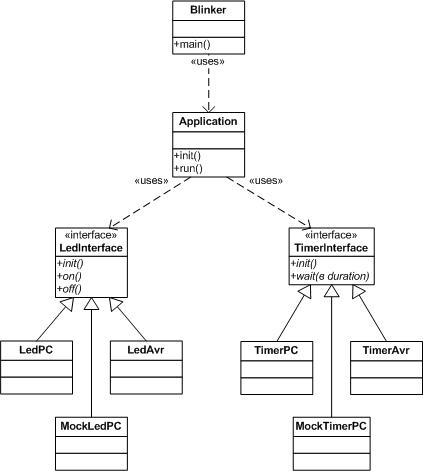
Лучше? Да, значительно. Во-первых, мы явно зафиксировали интерфейсы модулей нижнего уровня, и теперь мы сколько угодно можем менять их реализацию, не затрагивая при этом функциональность системы в общем. Так, главный цикл приложения даже не заметит, если мы перейдем с отсчета временных пауз через программную задержку на работу с аппаратным таймером по прерываниям; бизнес-логика при этом не изменится, хотя эффективность использования ресурсов в целом существенно возрастет. Во-вторых, мы развязали себе руки для создания мультиплатформенной реализации. Теперь мы можем выполнить максимум тестов на инструментальной платформе, оставив непротестированной лишь тонкую прослойку HAL. Остается нерешенной проблема, о которой мы уже говорили ранее, а именно: как писать тесты для модулей высокого уровня, которые зависят от еще не реализованных модулей низкого уровня? Впрочем, использование интерфейсов и эту проблему позволяет решить достаточно легко, ведь теперь добавить к проекту модули-двойники — вполне тривиальная задача (рис. 6):
В качестве тестовых двойников мы будем использовать подставные объекты (широко известные также как мок-объекты; впрочем, это понятие очень часто используется некорректно, и мок-объектами называют любые двойники, что, вообще говоря, неправильно). Для этого нам придется изучить новый для нас инструмент под названием CMock. Он неоднократно упоминался ранее в данной серии статей; пришла пора познакомиться с ним поближе. Продолжение: часть 4. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |