| Все для программирования. |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |
|
Каталог статей
|
Статья
Родная Библиотека Потоков POSIX для Linux подлатано saimhe От себя: огромное спасибо девушке из Одессы TRIGGER2003 за огромную помощь с переводом и редактору saimhe за указанные недочеты и ошибки. Сегодняшние требования к потокам едва ли могут быть удовлетворены библиотекой LinuxThreads, реализующей POSIX потоки, и являющейся в настоящее время частью стандартных runtime-ресурсов Linux системы. Она не написана на базе расширений ядра, которые существуют сейчас и появятся в ближайшем будущем, не масштабируется и не принимает во внимание современную архитектуру процессора. Необходима полностью новая модель, и эта статья вкратце опишет проект, придуманный нами. 1 Первая реализация Реализация LinuxThreads, которая сегодня является стандартной POSIX библиотекой потоков, основана на принципах, описанных разработчиками ядра во времена написания кода (1996). Основное предположение - что переключения контекста внутри связанных процессов достаточно быстры, чтобы обрабатывать каждый пользовательский поток одним потоком ядра. Процессы ядра могут иметь различные степени зависимостей. Спецификации потоков POSIX требуют совместного использования почти всех ресурсов. В связи с отсутствием потоковых ABI (application binary interface - прим. ред.) для используемых архитектур, настоящая реализация не использует регистры потока. Вместо того расположение локальной памяти потока определяется фиксированной связью между указателем стека и позицией дескриптора потока. Кроме того, должен быть создан поток-менеджер, способный осуществить правильную семантику сигналов, создания потоков, а также других различных частей управления процессами. Возможно, самая большая проблема была в отсутствии пригодных для использования примитивов синхронизации в ядре, что вынудило прибегнуть к использованию сигналов. Вместе с отсутствующей в нынешних версиях ядра концепцией групп потоков ядра это ведет к несоответствующему стандартам и неустойчивому управлению сигналами в библиотеке потоков. 2 Усовершенствования со временем Код библиотеки потоков был значительно улучшен за последующие шесть лет. Усовершенствования происходили в двух частях: ABI и ядро. Недавно внесённые расширения ABI позволяют использовать регистры потока или конструкции, которые могут работать подобно регистрам. Это было необходимым усовершенствованием, так как теперь определение местоположения локальных данных потока больше не является трудоёмкой операцией. Определить это местоположение необходимо почти для любой операции библиотеки потоков. Остальная часть runtime-ресурсов и пользовательских приложений также нуждается в этом. Для некоторых архитектур изменения были просты. Некоторые имели резервированные для этих целей наборы регистров, у других были особые характеристики процессора, которые позволяют сохранять значения в контексте выполнения. Но таких архитектур было немного, остальные же не имели ни того, ни другого. Эти архитектуры все еще полагаются на методе вычисления позиции локальных данных потока, основанном на адресе стека. Кроме медленных вычислений, это также означает невозможность реализации (для этой архитектуры) API, которые позволяли бы программисту выбирать позицию и размер стека. Эти интерфейсы особенно важны, когда одновременно или последовательно используются множество потоков. Стоит отметить решение, использованное для IA-32, из-за его нетривиальности; а так как эта архитектура несомненно является самой важной, это оказало влияние на проектирование библиотеки. В архитектуре IA-32, и так небогатой регистрами, есть два регистра, которые не были использованы в ABI: сегментные регистры %fs и %gs. Хотя непригодные для сохранения произвольных значений, они могут использоваться, чтобы обратиться к произвольным позициям виртуального адресного пространства процесса при помощи фиксированного смещения. Значение сегментного регистра используется, чтобы обратиться к некоторым структурам данных ядра, созданных для использования процессором, и которые содержат базовые адреса для каждого действительного индекса сегмента. С различными базовыми адресами можно обратиться к различным частям виртуального адресного пространства, используя то же самое смещение; это - именно то, что надо для доступа к локальным данным потока. Проблема с этим подходом состоит в том, что сегментные регистры должны поддерживаться некоторыми структурами данных, используемыми процессором. Базовый адрес сегмента сохранен в таблице дескрипторов. Обращение к этим структурам данных ограничено самой операционной системой, а не пользовательским кодом; это означает, что операции по изменению дескрипторной таблицы будут медленными. Контекстное переключение между различными процессами также стало медленнее, так как дополнительные структуры данных должны быть перезагружены при каждом переключении контекста. Также ядро должно выделять память для таблицы, что может быть проблематично из-за архитектуры памяти, если число элементов становится большим - таблица должна находиться в постоянно отображенной области памяти, а это иногда труднодостижимо. Кроме того, число различных значений в сегментном регистре, а потому и число различных адресов, которые могут быть предоставлены, ограничено 8192. В целом, использование "регистров потока" даёт бОльшую скорость, гибкость и завершенность API, но ограничивает число потоков и оказывает отрицательное влияние на производительность системы. Изменения, внесённые при разработке ядра до версии 2.4, идут от стабилизации к функциональности, что позволяет использовать сегментные регистры IA-32, а также усовершенствовать системный вызов clone(), который используется для создания потоков. Эти изменения можно было использовать для устранения некоторых требований для потока-менеджера, а также обеспечить правильную семантику в отношении идентификатора процесса - в частности, то, что идентификатор процесса един для всех потоков. Тем не менее, поток-менеджер не мог быть полностью устранён по ряду причин. Во-первых, освобождение памяти стека не может быть выполнено потоком, использующим эту память. Во-вторых, чтобы избежать зомби потоков ядра, завершившихся потоков надо дожидать при помощи wait(). Но пока эти проблемы и множество других не решены, не было сочтено нужным переписывать библиотеку потоков ради использования появившихся преимуществ. 3 Проблемы с существующей реализацией Существующая реализация показала себя достаточно хорошей для многих приложений, однако существуют и многочисленные проблемы, особенно во время интенсивного использования:
4 Цели новой реализации Попытка залатать существующую реализацию - цель, не заслуживающая внимания. Всё построено вокруг ограничений ядра Linux в то время. Необходима полная перезапись. Цель состоит в совместимости с ABI (что не является недоступным благодаря способу, которым реализованы API потоков POSIX). Но всё еще есть возможность переосмыслить каждое решение, сделанное при проектировании. Правильные решения тождественны знанию требований реализации. Подобранные требования включают в себя: Соответствие POSIX Соответствие с самым последним стандартам POSIX - наивысшая цель, позволяющая достигнуть совместимости исходного кода с другими платформами. Это не подразумевает, что расширения, выходящие за пределы спецификации POSIX, не могут быть добавлены. Эффективное использование SMP Одна из основных целей использования потоков - обеспечить использование возможностей многопроцессорных систем. Разбивая работу на столько частей, сколько центральных процессоров, в идеале можно обеспечить линейный прирост скорости. Низкие затраты на запуск Создание новых потоков должно иметь очень низкие затраты, чтобы создавать потоки даже для малых частей работы. Низкая цена связи Программы, отлинкованные с библиотекой потока (прямо или косвенно), но не использующие потоки, не должны быть сильно затронуты этим. Бинарная совместимость Новая библиотека должна быть совместима на уровне двоичного кода с реализацией LinuxThreads. Некоторые семантические разногласия неизбежны, так как эта реализация не соответствует POSIX. Аппаратная масштабируемость Реализация потоков должна работать достаточно хорошо с большим числом процессоров. Административные затраты не должны слишком возрастать с увеличением числа процессоров. Программная масштабируемость Другое применение потоков - решить подпроблемы выполнения пользовательского приложения в отдельных контекстах. В Java потоки используются для реализации окружающей среды программирования, так как асинхронные операции не поддерживаются. А результат от этого тот самый: могут быть созданы огромные количества потоков. Новая реализация в идеале не должна иметь никаких установленных пределов на число потоков или других объектов. Поддержка архитектуры машины Реализация для больших машин всегда была немного сложнее, чем для потребительских или господствующих машин. Эффективная поддержка этих машин требует близких к ОС ядра и кода пользовательского уровня, чтобы знать подробности об архитектуре машины. Процессоры в больших машинах, например, часто разнесены по отдельным узлам, и использование ресурсов на других узлах более дорого. Поддержка NUMA Один специальный класс будущих машин, представляющий интерес, основан на неоднородных архитектурах памяти (NUMA). Код, подобный библиотеке потоков, должен быть разработан с учетом этого, чтобы не упустить выгоды от использования потоков на машинах с такой архитектурой. Важна проектировка структур данных. Интегрирование с C++ C++ определяет обработку исключений, которая автоматически очищает объекты контекста, теряющихся при возникновении исключения. Этому процессу подобна отмена потока, и разумно ожидать, что отмена также вызывает необходимые объектные деструкторы. 5 Принятые решения Перед началом реализации должно быть принято множество решений, которые существенно повлияют на реализацию. 5.1 1-к-1 против M-к-N Наиболее важное решение, которое должно быть принято, состоит в выборе зависимости между потоками ядра и потоками пользовательского уровня. Не стоит упоминать об использовании потоков ядра, т. к. реализация чисто на пользовательском уровне не может использовать преимущества многопроцессорных машин, что является одной из описанных целей. Одна из возможностей - модель 1-к-1 старой реализации, где каждый поток пользовательского уровня имеет в качестве основания поток ядра. Вся библиотека потоков могла бы быть относительно тонким слоем над функциями ядра. Второй вариант библиотеки с моделью M-к-N, где число потоков ядра и потоков пользовательского уровня не должно иметь установленной связи. Такая реализация планирует потоки пользовательского уровня на доступных потоках ядра. Поэтому в работе находятся два планировщика. И если они не будут сотрудничать, то сделанные ими решения могут значительно понизить быстродействие системы. За эти годы были предложены различные схемы реализации взаимодействия. Самая многообещающая и в большинстве используемая - это схема Активации Планировщика. Здесь же эти два планировщика работают в команде: планировщик пользовательского уровня может давать подсказки планировщику ядра, в то время как планировщик ядра уведомляет планировщика пользовательского уровня о своих решениях. Разработчики ядра соглашались с тем, что модель M-к-N не вписывается в концепцию ядра Linux. Стоимость необходимой инфраструктуры слишком высока. Если позволить контекстное переключение в планировщике пользовательского уровня, то придется часто копировать содержание регистров пространства ядра. Наконец, множество проблем, которые планировщик пользовательского уровня помогает предотвращать, не являются проблемами для ядра Linux. Огромные число потоков - не проблема, так как планировщик и другие подпрограммы ядра имеют постоянное время выполнения, O(1), в противоположность линейному времени относительно числа активных процессов и потоков. Наконец, нельзя не учитывать затраты на реализацию дополнительного кода, необходимого для модели M-к-N. Особенно в отношении высокосложного кода, подобного библиотеке потоков, многое говорит в пользу чистой и тонкой реализации. 5.2 Обработка сигналов Другая причина использования модели M-к-N состоит в упрощении обработки сигналов в ядре. Несмотря на то, что обработчик сигнала (а тем самим и факт, будет ли сигнал проигнорирован) является свойством процесса, потокам свойственны индивидуальные маски сигналов. При тысячах потоков на процесс ядро потенциально должно проверять маски сигналов каждого потока, чтобы определить, можно ли выдать сигнал. Если сохранять низкое число потоков ядра с помощью модели M-к-N, то эту работу можно выполнить на пользовательском уровне. Однако обработка конечной выдачи сигнала на пользовательском уровне имеет несколько недостатков. Поток, который не ожидает данного сигнала, не должен уведомляться о его получении процессом. Сигнал может быть обнаружен, если для доставки сигнала используется стек потока и при этом поток получает ошибку EINTR от системного вызова. Первого можно избежать, используя дополнительный стек для доставки сигналов; с другой стороны, в распоряжении пользователя уже есть sigaltstack. Но оба трудно реализовать. Для предотвращения недопустимых EINTR, получаемых от системных вызовов, оболочки системных вызовов должны быть расширены, что приведёт к дополнительным накладным расходам для нормальных операций. Есть две альтернативы для сценария выдачи сигналов:
В качестве альтернативы ядро может осуществить обработку сигналов согласно POSIX. В этом случае ядро должно будет обрабатывать множество масок сигналов, но это будет единственной проблемой. Так как сигнал будет просто посылаться потоку, если он не заблокирован, никаких ненужных прерываний из-за сигналов не будет. Ядро, кроме того, находится в лучшей ситуации для определения, какой поток предпочтительней при получении сигнала. Очевидно, это помогает, только если используется модель 1-к-1. 5.3 Да или нет вспомогательному потоку-менеджеру В старой библиотеке потоков для всех видов внутренних работ использовался так называемый поток-менеджер. Поток-менеджер никогда не выполняет пользовательский код. Вместо этого все другие потоки посылают запросы на подобии, 'создать новый поток', которые централизованно и последовательно выполнялись потоком-менеджером. Это было необходимо, чтобы помочь реализовать правильную семантику при множестве проблем:
Не вынуждая преобразовывать в последовательную форму важные и часто выполняемые запросы, такие, как создание потока, можно ожидать существенного прироста производительности. Поток-менеджер может работать только на одном из центральных процессоров, так что любая синхронизация может вызвать серьезные проблемы масштабируемости на SMP системах, и еще большие проблемы масштабируемости на системах NUMA. Частая зависимость от потока-менеджера вызывает значительный прирост переключений контекста. Отсутствие менеджера потоков в любом случае упрощает систему. Поэтому цель для новой реализации должна состоять в том, чтобы избежать использования потока-менеджера. 5.4 Список всех потоков Старая реализация потоков Linux хранила список всех выполняющихся потоков, который иногда пересматривался для выполнения операции над всеми потоками. Самое важное применение списка - это уничтожение всех потоков после завершения процесса. Этого можно избежать, если ядро позаботится об уничтожении потоков во время существования процесса. Список также использовался для реализации функции pthread_key_delete. Если ключ удален вызовом pthread_key_delete и используется повторно, когда последующий вызов pthread_key_create возвращает тот же самый ключ, реализация должна удостовериться, что значение, связанное с ключом для всех потоков, равна NULL. Старая реализация достигала этого, активно очищая слоты с ответственными за потоки структурами данных во время удаления ключа. Это - не единственный способ реализации. Если нужно избежать списка потоков (или его пересмотра), то тогда должна быть возможность определить, нужен ли вызов деструктора или нет. Один из способов реализации этого - использование счетчиков поколений. Каждый ключ для хранилища потоков и памяти, выделенной для них в структурах данных потоков, имеет такой счетчик. При выделении ключ получает увеличенное значение счетчика поколений, и это новое значение сохраняется в структурах данных потока. Удаление ключа заставляет счетчик поколении снова увеличиться. Если поток завершается, то деструкторы будут выполняться только для потоков, у которых счетчик поколения соответствует счетчику в структуре данных потока. Так удаление ключа становится простой операцией приращения. Поддержки списка потоков полностью избежать нельзя. Чтобы реализовать функцию fork без утечек памяти, необходимо, что память, использованная для стеков и другой внутренней информации всех потоков кроме потока, вызывающего fork, была восстановлена. Ядро в этой ситуации помочь не может. 5.5 Примитивы синхронизации Реализация примитивов синхронизации типа мутексов, блокировок чтения-записи, условных переменных, семафоров, и барьеров требует некоторой формы поддержки ядром. Активное ожидание - не опция, так как потоки могут иметь различные приоритеты (в смысле числа занимаемых тактов процессора). По той же причине отказались от исключительного использования sched_yield. Сигналы были единственным жизнеспособным решением к старой реализации. Потоки блокировались в ядре до пробуждения сигналом. Этот метод имеет серьезные недостатки в отношении скорости и надежности, вызванные поддельными пробуждениями и ослаблением качества обработки сигналов в приложении. К счастью, несколько новых функциональных возможностей были добавлены к ядру для реализации всех видов примитивов синхронизации. Это футексы [Futex]. Основной принцип прост, но достаточно мощен, чтобы адаптироваться ко всем видам использования. Вызывающие программы могут быть блокированы в ядре и могут быть пробуждены или явно, в результате прерывания, или по таймауту. Мутексы могут быть быстро осуществлены в полудюжине команд, полностью на пользовательском уровне. Очередь ожидания поддерживается ядром. Нет дальнейшей необходимости в поддержании дополнительных структур данных пользовательского уровня, поддерживаемых и очищаемых в случае отмены. Другие три примитива синхронизации могут одинаково хорошо реализованы с помощью футексов. Кроме того, большой плюс использования футексов в том, что они работают на областях памяти совместного использования, и поэтому футексы могут быть разделены процессами, имеющими доступ к той же самой части памяти. Вместе с очередями ожидания это полностью управляется ядром и таким образом точно соответствует требованиям межпроцессных POSIX примитивов синхронизации. Поэтому теперь становится возможным реализовать часто спрашиваемую опцию PTHREAD_PROCESS_SHARED. 5.6 Распределение памяти Одна из целей библиотеки состоит в обеспечении низких затрат на запуск потоков. Наибольшей проблемой рационального использования времени вне ядра является память, необходимая для структур данных потоков, локальных хранилищ потоков и стека. Оптимизация распределения памяти выполнена в два этапа:
Единственный недостаток этой схемы состоит в том, что хендл потока является просто указателем на дескриптор потока и поэтому последовательно созданные потоки получают тот же хендл. Это может скрыть ошибки и привести к странным результатам. Если это действительно становится проблемой, то при выделении дескриптора потока можно переключится в режим отладки, что позволит избежать повторного получения того же хендла. Здесь не о чем беспокоится при стандартных условиях выполнения. 6 Усовершенствование ядра Даже ранние разрабатываемые версии ядра Linux 2.5.x не обеспечивали всех функциональных возможностей, необходимых для хорошей реализации потоков. Следующие изменения были добавлены в официальную версию ядра. Все эти изменения были сделаны в августе и сентябре 2002 Инго Молнаром (Ingo Molnar) как часть этого проекта. Проектирование функциональных возможностей ядра и библиотеки потоков всё время было совместным, чтобы гарантировать оптимальные интерфейсы между этими двумя компонентами.
7 Результаты Этот раздел представляет результаты двух совершенно различных измерений. Первое - измерение времени, необходимого для создания и уничтожения потока. Второе измерение рассматривает обработку конкурентных блокировок. Время создания и уничтожения потока измерено просто как время создания и уничтожения потоков при различных условиях. Конечно, с переменным числом потоков, существующих одновременно. Если достигнуто максимальное число параллельных потоков, то программа ждет уничтожения потока для создания нового. Это сохраняет требования к ресурсам на управляемом уровне. По возможности создается несколько новых потоков; точное число - вторая переменная в испытательном ряде. Алгоритм испытания: в каждом потоке верхнего уровня, которых от 1 до 20, создать от 1 до 10 дочерних. Мы повторяли операцию создания потока 100 000 раз - это было нужно только для измерения тестового времени, и не следует путать это с более ранними испытаниями по алгоритму 'запуск 100 000 параллельных потоков сразу'. В результате - таблица с 200 значений. Каждое значение проиндексировано по числу потоков верхнего уровня и максимальному числу потоков, которые каждый поток верхнего уровня может создать до необходимости ожидать завершения одного из них. Созданные потоки вообще ничего не делают, кроме как завершаются. Мы подводим итоги результатов теста, в двух таблицах. В обоих случаях мы сглаживаем одно измерение матрицы функцией минимума. Рисунок 1 показывает результаты для различного числа потоков верхнего уровня, создающих потоки, которые мы фактически считаем. Используется минимальное время выполнения для всех запусков с различным числом потоков, работающих параллельно. Как мы можем видеть, NGPT (next generation POSIX threading - прим. ред.) стало вдвое быстрей и поэтому действительно является существенным усовершенствованием LinuxThreads. Процесс создания потока в LinuxThreads был сложным и медленным. Удивительно, что разница для NPTL (native POSIX thread library - прим. ред.) является настолько большой, в четыре раза. Вторая сводка выглядит похоже. Рисунок 2 показывает минимальное необходимое время для некоторого количества дочерних потоков. Время определяется оптимальным числом потоков, используемых каждым потоком верхнего уровня. На этой диаграмме мы видим эффект масштабируемости. Если слишком много потоков параллельно пробуют создать еще больше потоков, то все реализации страдают от этого, одни больше, другие меньше. Состязательная обработка. Рисунок 3 показывает время выполнения программы, которая создает 32 потока и переменное число критических секций, к которым потоки пробуют получить доступ (всего 50 000 попыток) [csfast]. Чем меньше критических секций, тем выше вероятность конкуренции. Диаграмма показывает существенные колебания, даже при усреднённых 6-ю запусками значениях. Эти колебания вызваны эффектами планирования, воздействующими на программы, которые не выполняют никакой реальной работы, а вместо этого тратят время на создание ситуации планирования (как блокирование на мутексах). Результаты для двух версий ядра показывают:
 Рисунок 1: изменение числа потоков верхнего уровня Производительность при создании и уничтожении потоков 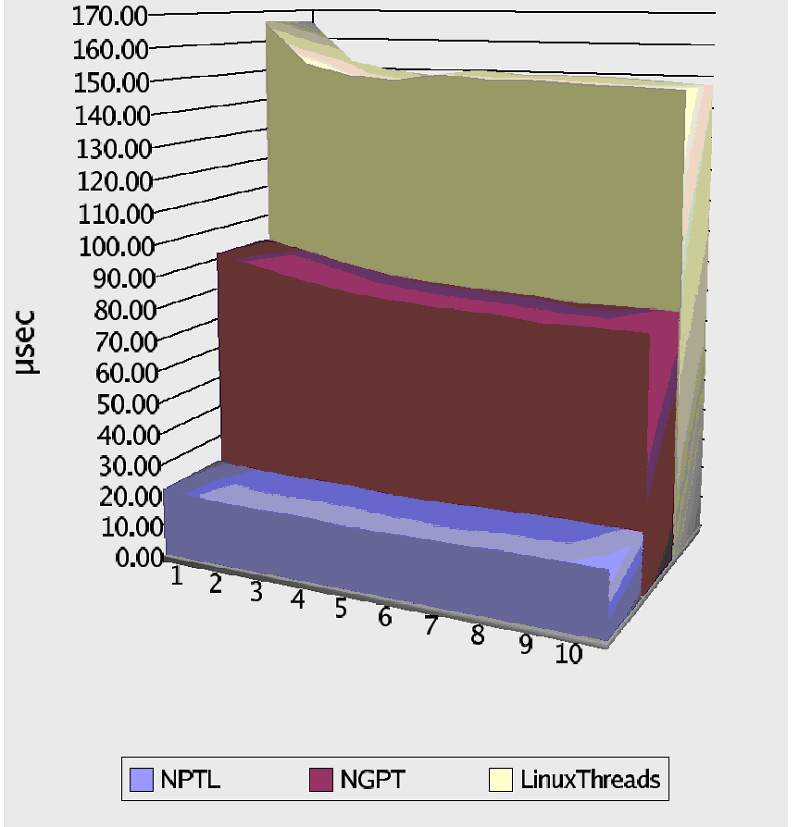 Рисунок 2: изменение числа совместно действующих дочерних потоков Производительность csfast5a 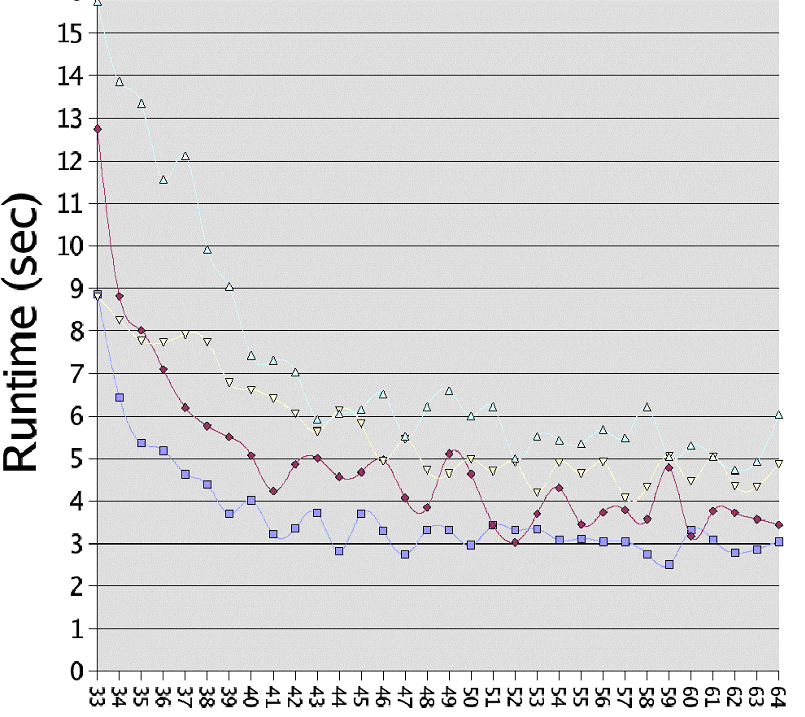 Количество критических секций  Рисунок 3: обработка состязательных блокировок 8 Остающиеся вопросы Остаётся несколько вопросов, прежде чем будет достигнута 100 % совместимость с POSIX. Изменения будут зависеть от того, как хорошо решение вписывается в реализацию ядра Linux. Семейства системных вызовов setuid и setgid должны воздействовать на весь процесс, а не только на начальный поток. Уровень nice является свойством всего процесса и после корректировки должно воздействовать на все потоки процесса. Предел использования CPU, который может быть выбран с помощью setrlimit, ограничивает совместное время, потраченное всеми потоками в процессе. Поддержка реального времени в библиотеке главным образом отсутствует. Системные вызовы для выбора параметров планирования доступны, но они не дают никакого эффекта. Причина для этого состоит в том, что большая часть ядра не следует правилам планирования в реальном масштабе времени. Пробуждение одного из потоков, ожидающего футекс, не выполняется по приоритету ожидания. Есть дополнительные места, где ядро упускает адекватную поддержку реального времени. По этой причине текущая реализация не замедлена поддержкой чего-либо, что не может быть достигнуто. Новая библиотека содержит множество мест с настраиваемыми переменными. В реальных ситуациях следует разумно определить их значения по умолчанию. Ссылки Этот материал лежит здесь http://people.redhat.com/drepper/nptl-design.pdf (301 кБ) |
| начало | почта | статьи | файлы | ссылки | сайты | RSS | о нас | опубликовать | оформление | авторы | друзья | реклама |